6 функций SSMS, которые заслуживают немного внимания
Новые версии SSMS полны очень интересных функций. С появлением SQL Server 2019 это нормально, когда мы фокусируемся на новых функциях ядра СУБД, однако SSMS также может предложить многое.
Давайте выделим некоторые очень интересные функции, которые этот инструмент может предложить в своих новых версиях.
Оценка уязвимости (Vulnerability Assessment)
Иногда конфигурация сервера и базы данных кажется очень сложной, особенно в отношении безопасности.
Функция оценки уязвимости анализирует 53 потенциальных проблемы, определяет, является ли конфигурация правильной или нет, и если нет, классифицирует риск проблемы.
Оценка может быть сделана для каждой базы данных, а отчеты могут быть сохранены в формате JSON, а затем снова открыты.
Для каждой потенциальной проблемы отчет объясняет проблему и предоставляет запрос, используемый для проверки наличия проблемы в базе данных.
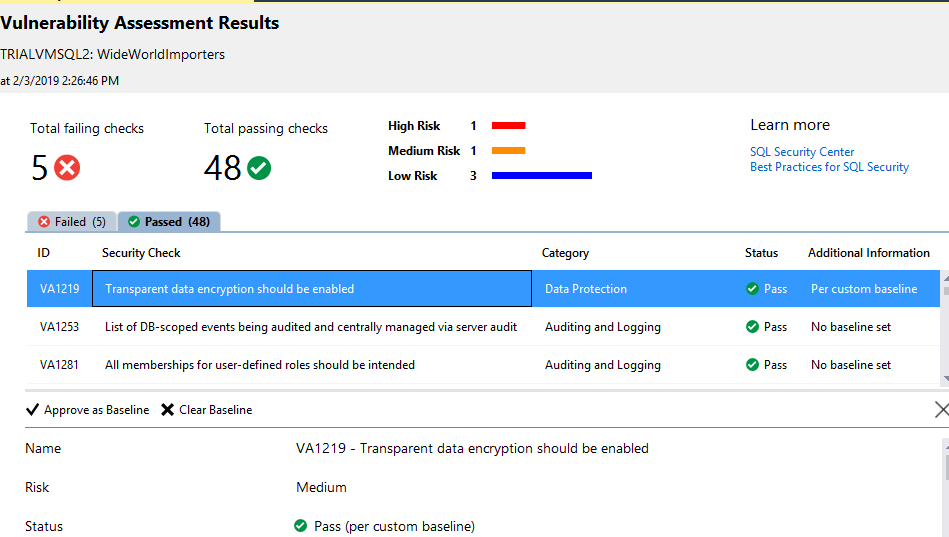
Этот инструмент также позволяет нам записывать результат в качестве базового показателя для нашей среды. Таким образом мы уберем нашу пользовательскую конфигурацию и потребности, чтобы они не были описаны как проблемы уязвимости. Однако это слабое место инструмента: базовые показатели хранятся в файле JSON в той же папке отчета об уязвимостях. В результате, если вы запустите отчет с разных клиентских компьютеров, вы можете получить разные результаты, игнорируя предыдущие базовые показатели, которые были сохранены.
Вы можете прочитать больше об этой функции по этой ссылке
Статическая маскировка данных
GDPR ввел много ограничений на то, как мы управляем нашими данными. Например, мы не можем использовать производственные данные для тестирования новых версий нашего приложения. Динамическое маскирование данных было началом, но иногда нам действительно нужно скрывать данные, создавать копию базы данных, заменяя некоторые поля фиктивными данными. Это статическая маскировка данных.
Эта новая функция позволяет нам выбирать, какие столбцы мы хотим замаскировать, выбирать функцию маски и запускать процесс, который создаст замаскированную резервную копию базы данных, которую мы, например, можем предоставить команде тестировщиков.
Вы можете прочитать более подробную информацию по этой ссылке
Обнаружение и классификация данных
В эпоху GDPR и других подобных законов во всем мире становится все более и более важным точно определить, какие именно данные у нас есть в наших базах данных, являются ли они общедоступными, конфиденциальными и так далее.
В этом нам помогает функция обнаружения и классификации данных. Во-первых, она пытается автоматически определить, какие поля являются чувствительными, и рекомендовать классификацию для них. Мы можем установить классификации для рекомендуемых полей и каких-либо еще.
Для каждого поля можно установить две метки: тип информации и уровень чувствительности, последняя включает уровни GDPR.
Кроме того, мы можем добавить обе метки для любого поля в модели, даже если оно изначально не идентифицировалось как чувствительное.
Все классификации хранятся в двух системных таблицах: sys_information_type_name и sys_sensitivity_label_name
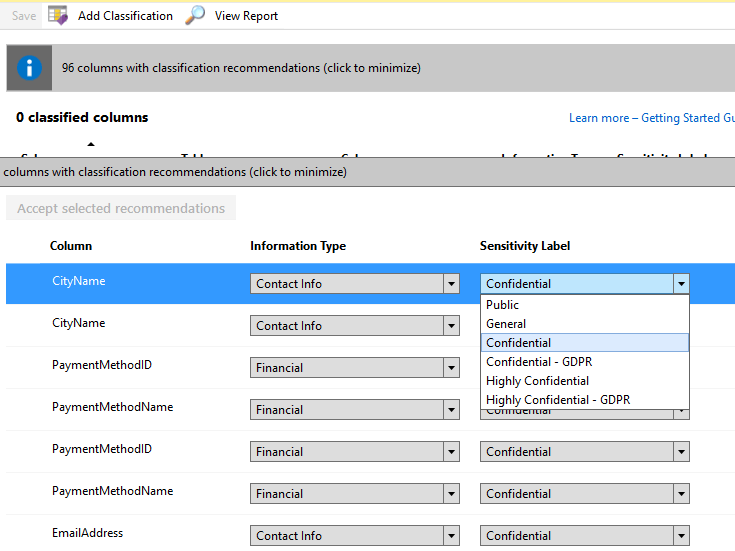
Это интересная функция, отчеты кажутся интересными, но это функция моделирования, и SSMS не хватает многих функций моделирования, даже диаграммы баз данных устарели. Есть сомнения относительно того, насколько полезной будет функция моделирования внутри SSMS.
Вы можете узнать больше об этой функции по этой ссылке.
Обновление базы данных
Это, наверное, самая мощная новая функция в SSMS. Каждая версия SQL Server содержит много обновлений в оптимизаторе запросов, однако оптимизатор запросов настолько мощен, что, хотя большинство запросов может быть улучшено, некоторые из них могут иметь проблемы с производительностью. Начиная с SQL Server 2016, была разработана процедура для следующих ситуаций:
- После переноса базы данных в новую версию сохраните ее на прежнем уровне совместимости.
- Используйте хранилище запросов в течение некоторого времени, чтобы создать базовую линию для выполнения запросов.
- Измените уровень совместимости на новую версию
- Подождите, чтобы захватить выполнение запроса
- Исправьте регрессии запросов, применяя старые планы запросов
Эта функция, также называемая Query Tunning Assistant или QTA, помогает нам выполнить этот процесс. Помните, что этот процесс может занять много дней или недель, чтобы захватывать рабочую нагрузку дважды, до и после изменения модели совместимости. Эта функция создает сеанс обновления, рекомендует лучшую конфигурацию для хранилища запросов и выполняет захват рабочей нагрузки.
Лучшая часть - это конец процесса: QTA не ограничивается принудительным использованием старых планов запросов, в этом случае мы могли бы выполнять все задачи, используя хранилище запросов самостоятельно. QTA может анализировать регрессивные запросы и выявлять многие известные регрессионные проблемы и предлагать создание руководств по плану для их решения.
Этот способ намного более подробный, чем тот, которым мы могли бы воспользоваться сами, используя серверные инструменты, что делает эту функцию очень полезной.
Интеграция с Azure Data Studio
Azure Data Studio - это новый инструмент Microsoft, который обеспечивает доступ не только к SQL Server, но и ко многим различным источникам данных как в облаке, так и локально. Пока не ясно, каковы будущие отношения между SSMS и Azure Data Studio, но теперь SSMS имеет возможность открывать то же соединение в Azure Data Studio, переходя от одного инструмента к другому.
При работе с SSMS вы можете одним щелчком мыши открыть тот же сервер в Azure Data Studio, щелкнув правой кнопкой мыши на соединение.
Открыть папку
SSMS является дочерней версией Visual Studio, она наследует множество поведений Visual Studio, включая шаблон для работы с файлами решений. Хотя это интересно, администраторы баз данных не используют файлы решений, они хранят свои сценарии в файлах .SQL, организованных в разные папки, и на этом все.
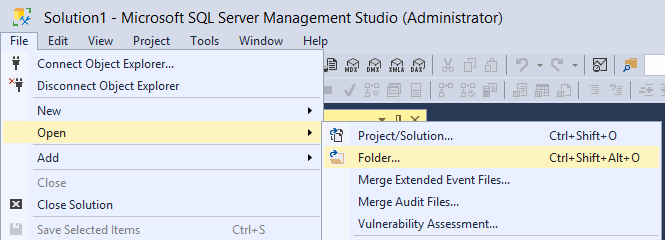
Разрешение администраторам баз данных открывать папки в качестве решения облегчает нашу жизнь и помогает нам в организации наших сценариев.