Автоматизированное машинное обучение с SQL Server с Azure Machine Learning
Недавно мы написали в блоге об автоматизированном машинном обучении на кластерах больших данных SQL Server 2019. В сегодняшней статье мы представим дополнительный подход к автоматическому машинному обучению, использующий службу машинного обучения Azure (Azure ML), вызываемую из SQL Server. Хотя в предыдущем посте речь шла о реализации на основе Spark, настроенной на большие данные, в этом посте представлен подход, который выполняется непосредственно в SQL Server, работающем на одном сервере. Это хорошо подходит для использования с данными, хранящимися в таблицах SQL Server, и обеспечивает идеальное решение для любой версии SQL Server, которая поддерживает службы машинного обучения SQL Server.
Служба машинного обучения Azure
Служба машинного обучения Azure - это облачная служба. Мы вызываем службу из SQL Server, чтобы управлять и направлять автоматизированное обучение моделям машинного обучения в SQL Server. Автоматизированное машинное обучение пробует множество конвейеров машинного обучения. Оно выбирает конвейеры, используя собственную модель машинного обучения, основываясь на результатах предыдущих конвейеров. Автоматизированное машинное обучение можно использовать в службах машинного обучения SQL Server, таких средах Python, как ноутбуки Jupyter и Azure notebooks, блоки данных Azure и Power BI.
Начиная с SQL Server 2017, SQL Server включает возможность запуска кода Python с помощью хранимой процедуры sp_execute_external_script. Это позволяет SQL Server вызывать автоматическое машинное обучение Azure ML. Инструкции и код для запуска следующего примера доступны на GitHub.
Пример: прогнозирование спроса на электроэнергию
Автоматизированное машинное обучение может использоваться для регрессии (прогнозирования непрерывных значений), классификации или прогнозирования. Этот пример фокусируется на прогнозировании спроса на электроэнергию, где целью оператора энергосети является прогнозирование будущего спроса на энергию с учетом прогнозируемых погодных данных. Хотя контекст нашего примера - прогнозирование спроса на энергию, используемые методы могут применяться во многих других контекстах и случаях использования.
В этом примере используется набор данных о потреблении энергии, состоящий из таблицы с четырьмя столбцами: timeStamp, demand, deg и temp. Мы используем три хранимые процедуры Transact-SQL, включая AutoMLTrain, AutoMLGetMetrics и AutoMLPredict. Процедура AutoMLTrain возвращает модель, которая прогнозирует столбец метки - в данном случае, спрос - на основе оставшихся столбцов, которые включают timeStamp, deg и temp. Здесь мы запускаем процедуру AutoMLTrain, используя данные в строках с отметкой времени до 1 февраля 2017 года:
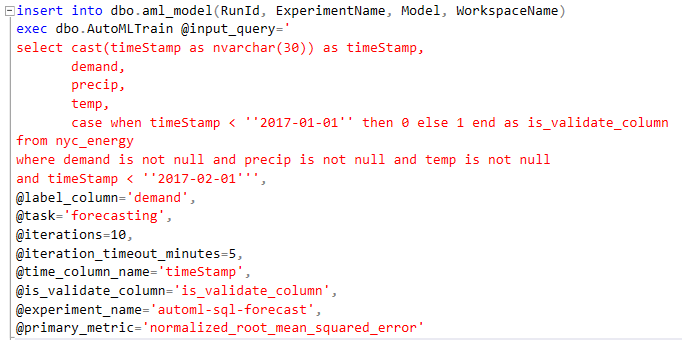
Полученная модель сохраняется в таблице SQL Server, чтобы ее можно было использовать позже для прогнозирования. Обучение можно просмотреть на портале Azure в рабочих пространствах службы машинного обучения:
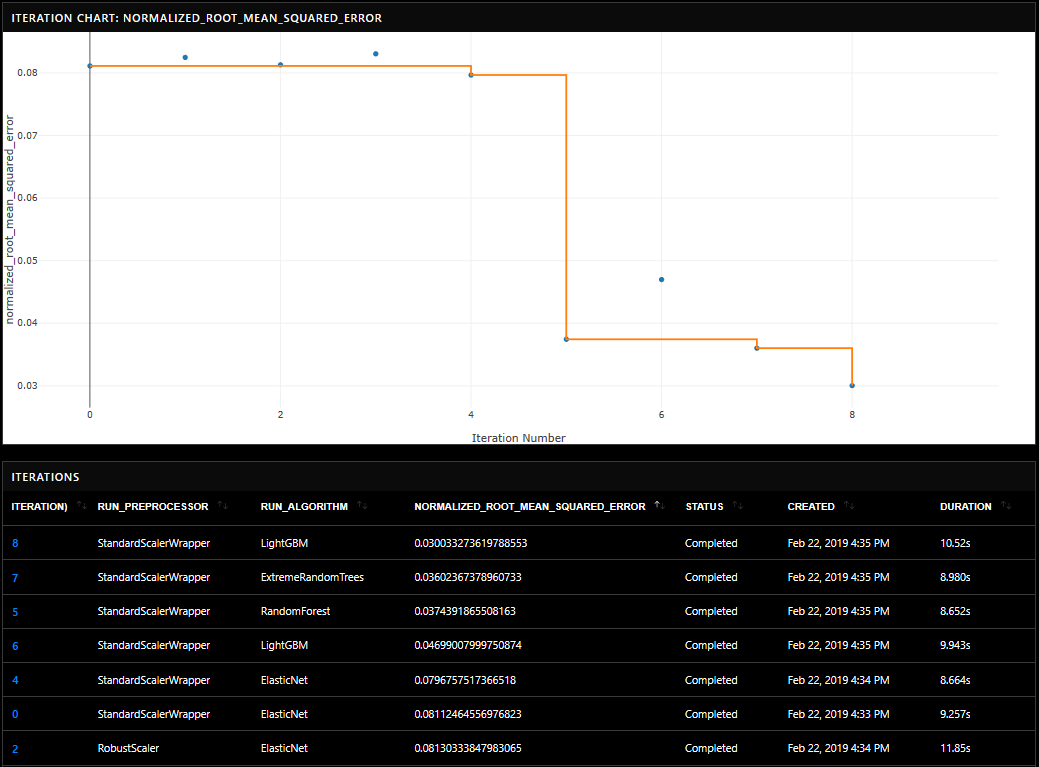
Необязательные параметры в AutoMLTrain допускают явное разделение обучения / проверки, перекрестную проверку, веса выборки, количество итераций, счет выхода, модели черного и белого списков, прогнозирование и ограничения по времени.
Хранимая процедура AutoMLGetMetrics возвращает несколько метрик для каждого конвейера. Они могут храниться и запрашиваться в SQL Server.
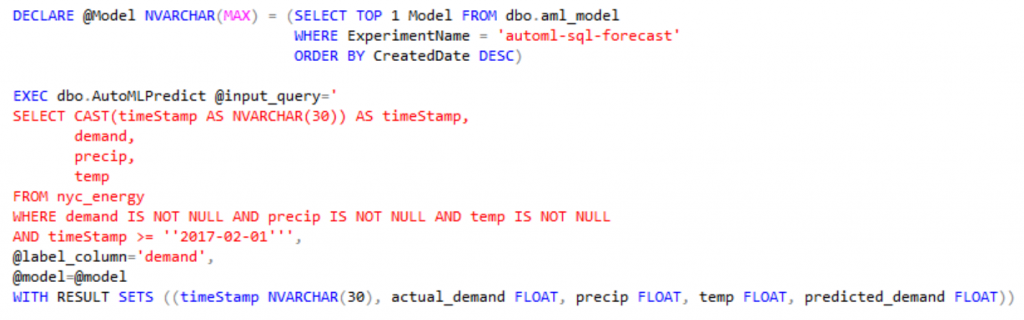
Наконец, хранимая процедура AutoMLPredict может прогнозировать новые значения на основе модели, возвращаемой AutoMLTrain. Изучив нашу модель с использованием данных до 1 февраля 2017 года, мы прогнозируем спрос на 1 февраля 2017 года и позднее:
Заключение
В этом сообщении мы увидели, как автоматизированное машинное обучение Azure ML можно использовать из SQL Server для обучения моделей, а затем прогнозировать новые значения. Разработчики SQL Server теперь могут обучать и использовать модели машинного обучения без необходимости изучать Python и без подробных знаний машинного обучения.