
В последнем посте мы объяснили, как работать с Azure Databricks. В этом посте я покажу RFR:
1- Загрузить данные в Azure data Lake Store
2- получить данные от Azure Data Lake Store в Azure Data Bricks
3- чистить данные с языком Scala
4- визуализировать с помощью языка R
5- осуществлять прогностический анализ с R
В следующем посте я объясню, как показать результат в Power BI.
Загрузка данных Azure data Lake Store
Вы должны создать модуль Azure Data Lake Store в Azure Portal.
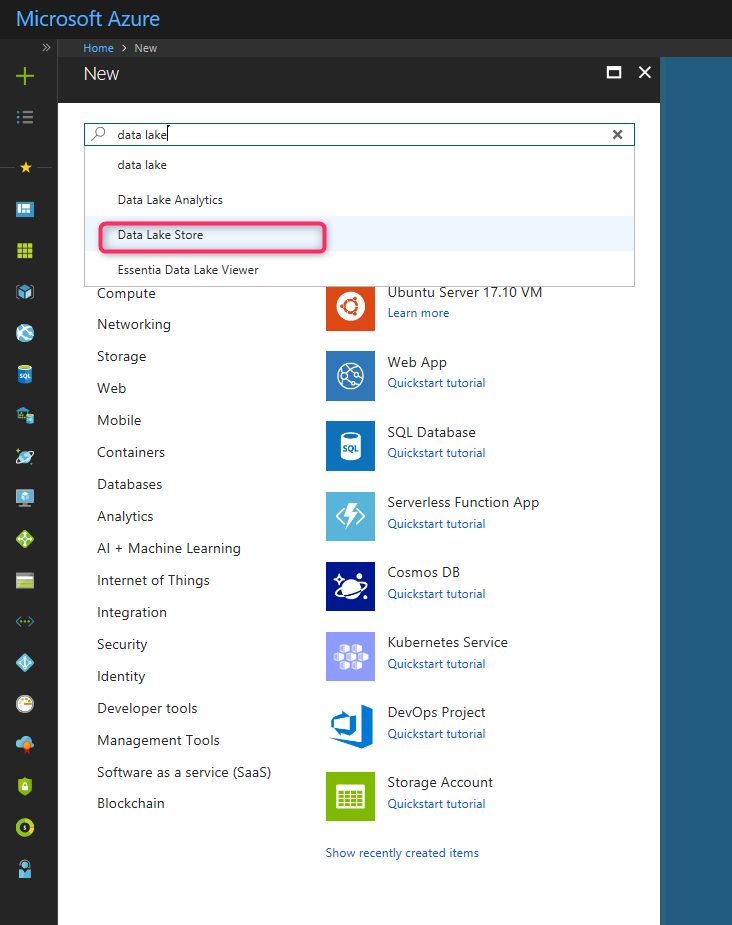
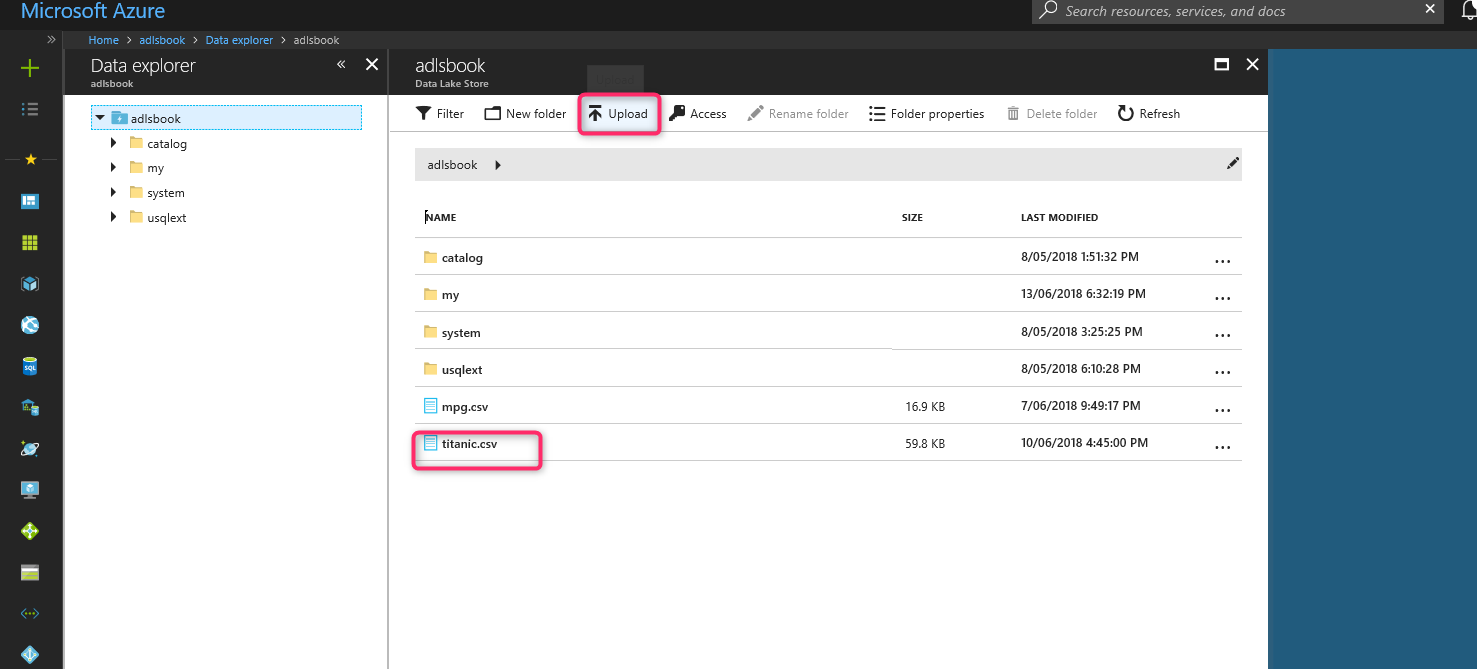
После создания Azure Data Lake Store загрузите набор данных Titanic.

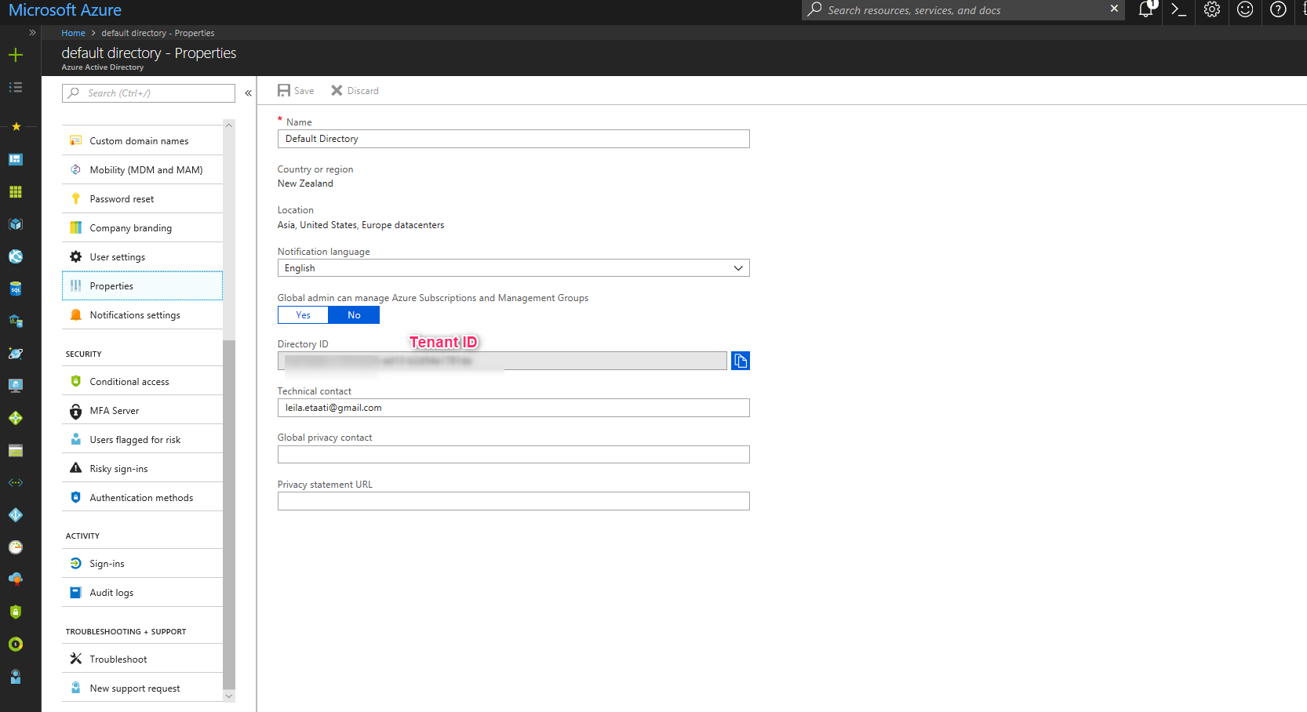
Теперь нам нужно получить ID аутентификации, ID клиента и ID арендатора.
Для ID клиента вам необходимо сначала создать приложение в активном каталоге Azure.

Затем скопируйте ID приложения.
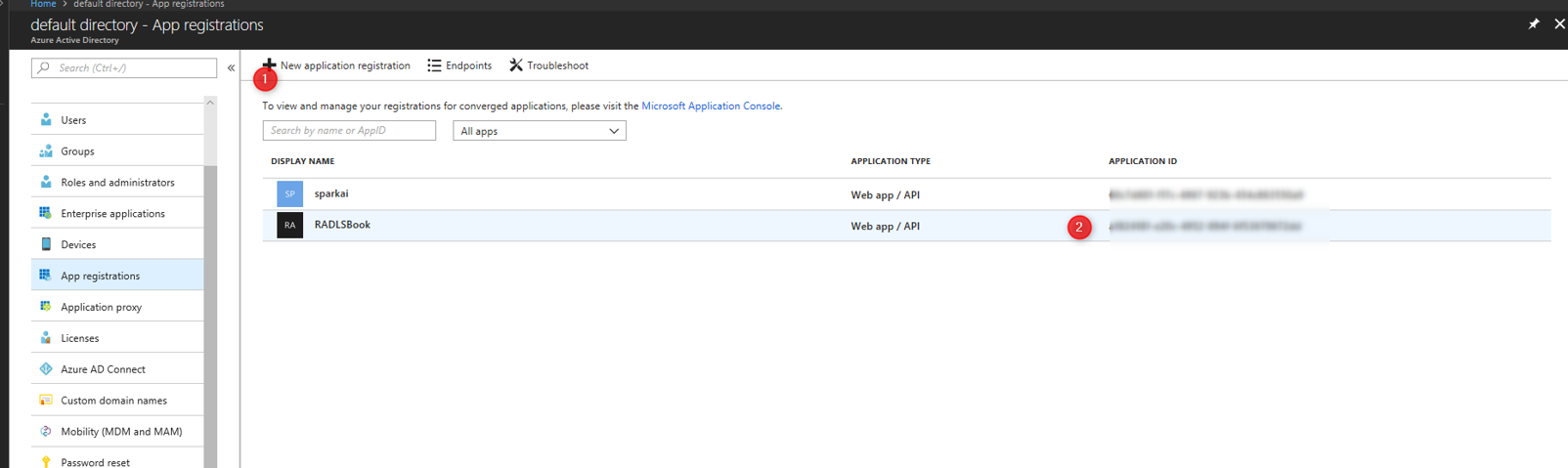
Затем скопируйте идентификатор приложения в Azure Active directory - регистрацию приложения.
Затем нажмите на созданную регистрацию приложения, выберите Keys и создайте новый ключ. Скопируйте ключ как ключ аутентификации.
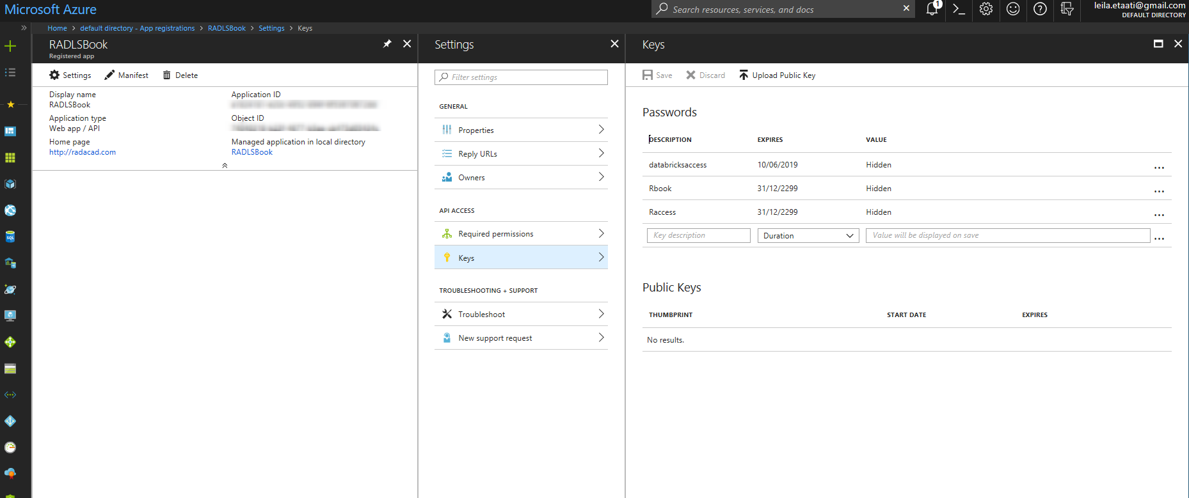
После создания ключа аутентификации, вам нужно создать ID арендатора щелкнув по свойствам в активном идентификаторе каталога, как показано ниже.
Теперь мы должны создать новый ноутбук в портале Azure Databricks с языком R.
Чтобы прочитать данные из Azure Data Lake Store, нам нужно установить некоторые учетные данные, как показано ниже.
spark.conf.set(“dfs.adls.oauth2.access.token.provider.type”, “ClientCredential”)
spark.conf.set(“dfs.adls.oauth2.client.id”, “<Application ID>”)
spark.conf.set(“dfs.adls.oauth2.credential”, “<Authentication Token>”)
spark.conf.set(“dfs.adls.oauth2.refresh.url”, “https://login.microsoftonline.com/<Tenant ID>/oauth2/token”)
val df=spark.read.option(“header”, “true”).csv(“adl://adlsbook.azuredatalakestore.net/titanic.csv”)
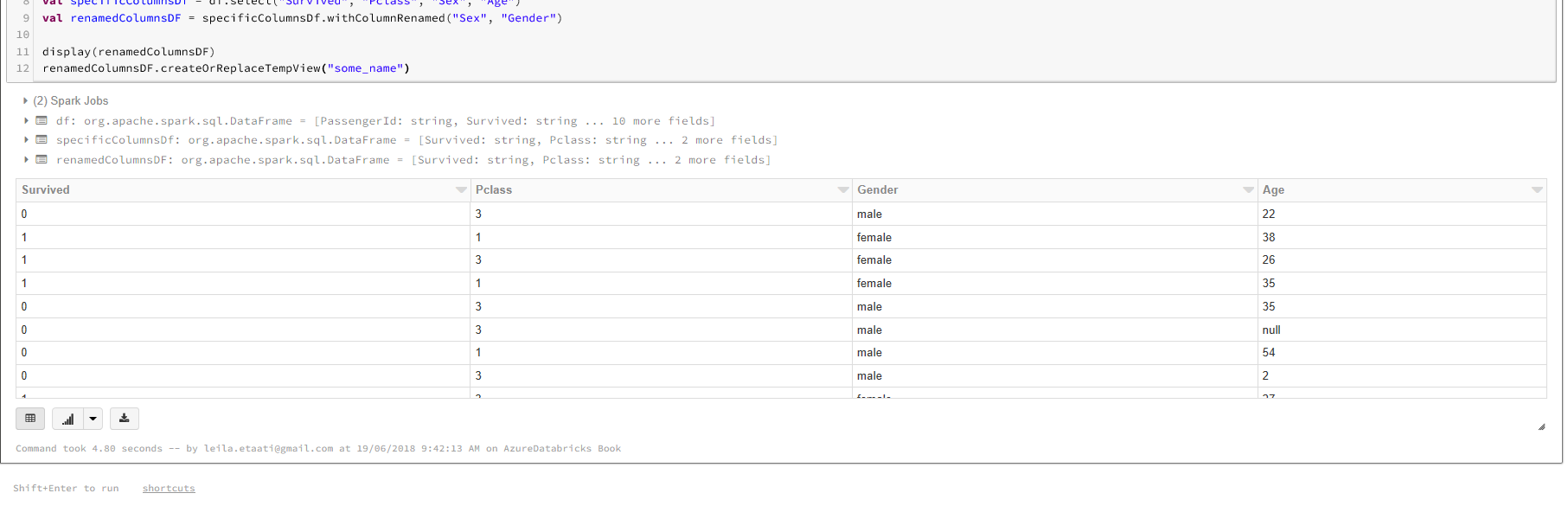
Набор данных в хранилище данных Azure Data будет храниться в переменной df. Для работы с наборами данных Titanic нам нужно выбрать столбцы Survived, Sex,Age, и PClass.
val specificColumnsDf = df.select(“Survived”, “Pclass”, “Sex”, “Age”)
val renamedColumnsDF = specificColumnsDf.withColumnRenamed(“Sex”, “Gender”)
Теперь нам нужно запустить R-коды для этих данных в другой ячейке, чтобы создать модель и предсказать, что пассажир с конкретным возрастом, полу и пассажирским классом выживет или нет. Необходимо передать данные из Scala в R. Для этого нам нужно создать временную таблицу, чтобы передать таблицу R-коду, используя следующий код:
renamedColumnsDF.createOrReplaceTempView(“some_name”)
Добавьте новую ячейку, щелкнув знак «плюс» в последней ячейке.
В новой ячейке нам нужно написать R-коды. В результате мы должны указать язык, поставив %r в начале кодирования. Кроме того, мы используем некоторые пакеты из SparkR. Затем мы используем функцию SQL для извлечения данных из последней ячейки Scala. Наконец, сохраните данные в переменной набора данных.
%r
library(SparkR)
sql(“REFRESH TABLE some_name”)
df <- sql(“SELECT * FROM some_name”)
dataset<-as.data.frame(df)
display(df)
В одной и той же ячейке или новой вы можете написать несколько кодов для машинного обучения. В этом примере мы надеемся проверить выживут ли пассажиры с конкретным классом, возрастом или полом. Для дерева решений есть пакет rpart. Этот пакет помогает нам прогнозировать вероятность выживания.
%r
library(SparkR)
sql(“REFRESH TABLE some_name”)
df <- sql(“SELECT * FROM some_name”)
dataset<-as.data.frame(df)
library(rpart)
DT<-rpart(Survived~.,data=dataset,method=”class”)
test<-dataset[,2:4]
Prediction<-predict(DT,test)
output<-data.frame(test,Prediction)
display(output)
При запуске ячейки будет отображаться вывод:
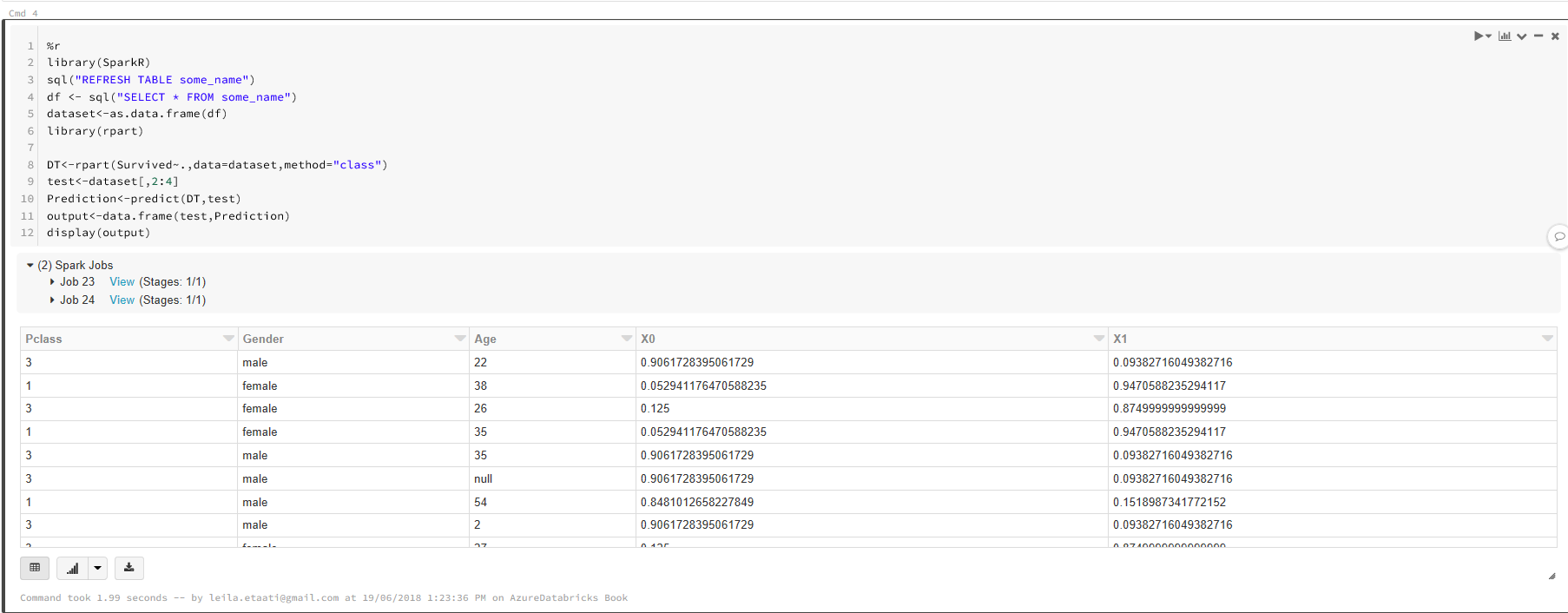
Существует возможность рисовать некоторые диаграммы, используя R-пакеты, такие как ggplot2. Например, если мы хотим видеть Pclass, Age и Gender в диаграмме рассеивания с определенной легендой, мы можем использовать приведенные ниже коды.
%r
display(output)
library(ggplot2)
ggplot(output,aes(x=output$Age,y=output$Pclass, color=output$Gender))+geom_jitter()
Как вы можете видеть на рисунке ниже, будет показана диаграмма рассеивания с легендой для пола.
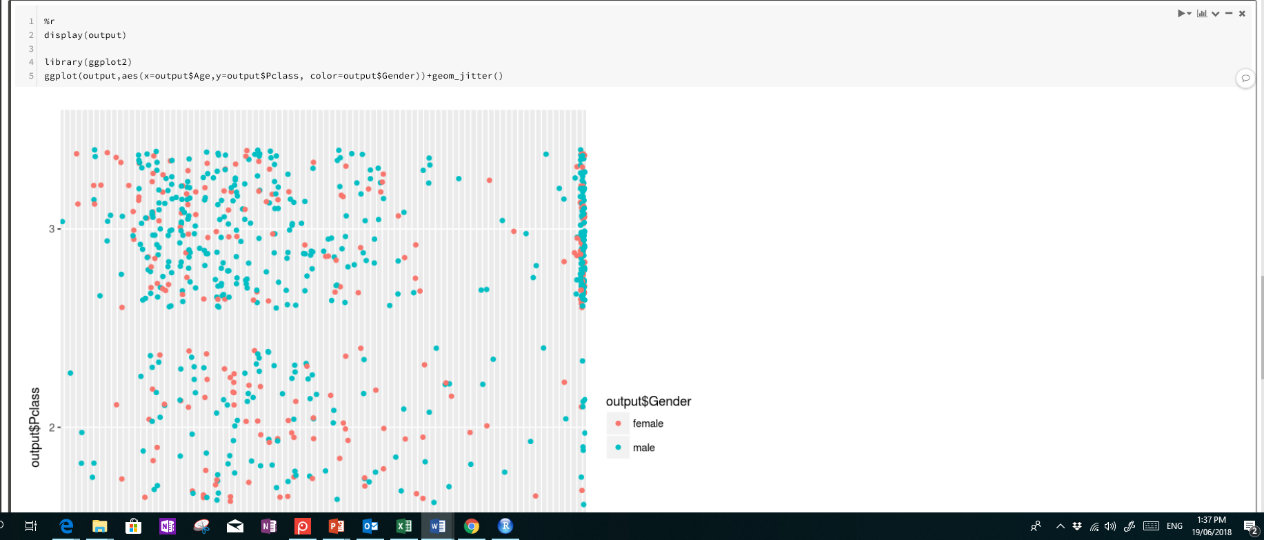
Azure Databricks предназначен не только для машинного обучения, он также предоставляет возможность получать данные из разных ресурсов для использования изменений, а затем показывает результат в некоторых инструментах визуализации, таких как Power BI. Кроме того, есть возможность запланировать процесс
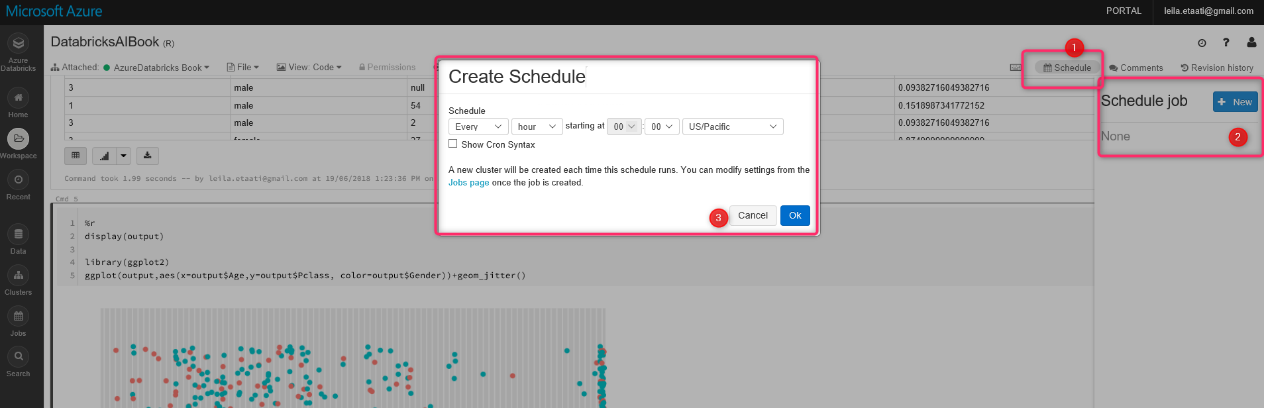
Существуют различные способы получения данных из базы данных SQL, услуг Azure, таких как Azure Blob, Data Lake Store, Azure Cosmos и т. д.