Что нового в SQL Server 2019: более быстрые переменные таблицы (и новые проблемы с параметром Sniffing)
Более десяти лет обработка табличных переменных SQL была плохой. Чтобы продемонстрировать, насколько ужасная оценка мощности, используем этот запрос Stack Overflow:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
declare @VoteStats table (PostId int, up int, down int)
insert @VoteStats
select
PostId,
up = sum(case when VoteTypeId = 2 then 1 else 0 end),
down = sum(case when VoteTypeId = 3 then 1 else 0 end)
from Votes
where VoteTypeId in (2,3)
group by PostId
select top 100 p.Id as [Post Link] , up, down
from @VoteStats
join Posts p on PostId = p.Id
where down > (up * 0.5) and p.CommunityOwnedDate is null and p.ClosedDate is null
order by up desc
GO
|
Он помещает кучу данных в переменную таблицы, а затем запрашивает ту же переменную таблицы. В небольшой базе данных StackOverflow2010 это занимает почти целую минуту и делает почти миллион логических чтений. Вот план:
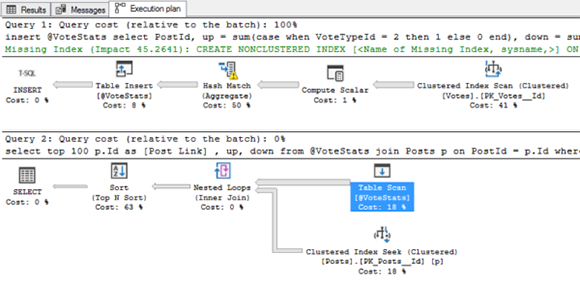
Посмотрите, как верхний запрос имеет стоимость относительно партии 100%, а второй запрос говорит 0%? Да, это порочная ложь: она основана на приблизительной стоимости запросов, даже если вы смотрите на фактический план. Коренной причиной является количество строк, которые SQL Server ожидает найти в переменной таблицы во втором запросе - наведите указатель мыши на это:
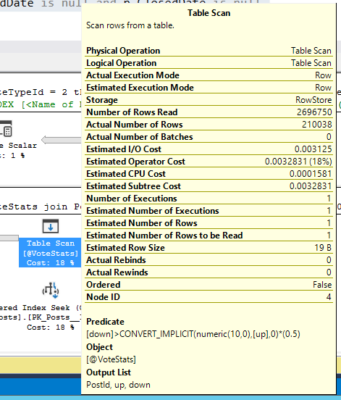
Оценочное количество строк только одностороннее, потому что мы только что вставили в него 2,7 млн. строк. В результате SQL Server говорит: «Я просто получу одну строку из переменной таблицы, сделайте одно соответствие индексу в таблице Posts, а затем мне не нужно будет сортировать эти данные в плане».
Раньше единственно известным решением было исправление этого за счет замены переменных таблиц временными таблицами или через нажатие OPTION RECOMPILE на соответствующих участках серии. Однако и то, и другое требует изменения запроса, что не всегда возможно.
Теперь давайте попробуем это в SQL Server 2019.
Тот же запрос, никаких изменений, просто запуск его в базе данных с уровнем совместимости 150:
- Продолжительность: раньше было 57 секунд, теперь 7 секунд с 2019
- Логические чтения: раньше было ~ 1 млн, теперь около 70 тыс. с 2019
Вот план запросов SQL Server 2019:
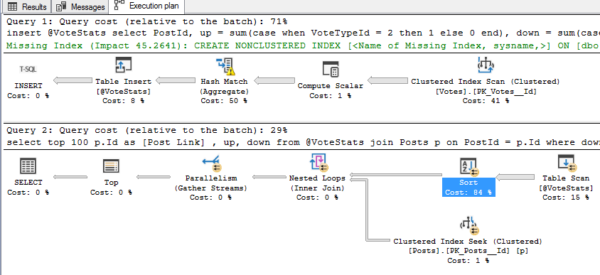
Теперь, по оценкам SQL Server 2019, из таблицы будет выходить 800 тыс. строк, которые все еще не совсем точны, но, по крайней мере, намного точнее, чем оценка 1 строки. В результате он решает сортировать содержимое переменных таблицы, чтобы найти первые 100 строк FIRST перед выполнением запросов в таблице Posts.
Внезапно 2019 дает лучшие оценки переменных таблицы из коробки.
Теперь у нас есть новая проблема: параметр sniffing.
Давайте создадим индекс для Users.Location, чтобы помочь SQL Server понять, сколько строк вернется, если мы фильтруем для данного местоположения. Затем мы создадим хранимую процедуру с двумя запросами:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE INDEX IX_Location ON dbo.Users(Location); GO CREATE OR ALTER PROC dbo.usp_TableVariableTest @Location NVARCHAR(40) AS BEGIN DECLARE @NotATable TABLE (ID INT); INSERT INTO @NotATable SELECT Id FROM dbo.Users WHERE Location = @Location; SELECT u.* FROM @NotATable t INNER JOIN dbo.Users u ON t.ID = u.Id ORDER BY u.DisplayName, u.Location, u.WebsiteUrl; END GO |
Первый запрос загружает переменную таблицы со всеми пользователями в местоположении.
Второй запрос извлекает строки из этой переменной таблицы, выполняет поиск и сортирует данные. Это означает, что SQL Server должен оценить, сколько памяти необходимо предоставить для операции сортировки.
Давайте освободим кэш плана, а затем позвоним ему для действительно большого местоположения:
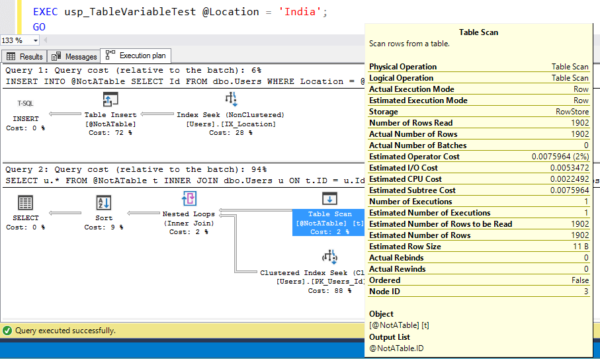
Здесь мы навели указатель мыши на проверку переменных таблицы, чтобы показать приблизительное и фактическое количество строк - они абсолютно идеальны! Это круто! Это означает, что SQL Server выделяет достаточно памяти для сортировки этих 1902 строк.
Теперь давайте запустим его для очень небольшой локации:
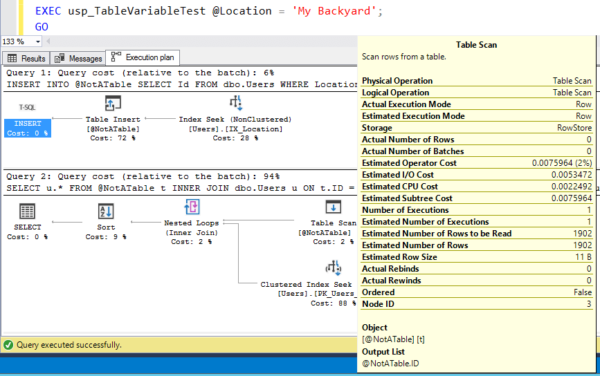
Так же, как и каждый параметр sniffing issue с самого начала, SQL Server кэшировал план выполнения для первого набора параметров, которые были отправлены. Теперь он оценивает 1,902 строки - из Индии - каждый раз, когда выполняется запрос. Здесь это не сложно, когда переоценка памяти для этого запроса невелика, но теперь давайте попробуем ее в обратном порядке.
Освободите кэш плана, сначала запустите его для My Backyard, а SQL Server 2019 кэширует план выполнения для оценки с 1 строкой:
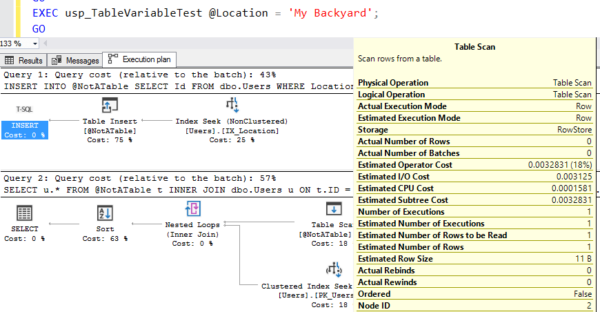
А затем запустите его для Индии, и готово: сортировка выплескивается на диск:
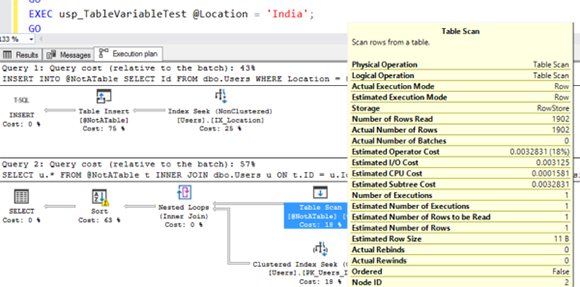
Индия повторно использует план оценки в 1 ряд
В большинстве случаев обработка табличной переменной SQL Server 2019 будет быстрее.
Раньше переменные таблицы обычно производили плохие планы ВСЕГО времени. Это было черно-белое. Производительность была ни о чем.
Начиная с SQL Server 2019, у нас больше шансов получить хорошие планы, по крайней мере, во многих случаях, если не в большинстве. У нас просто есть новая проблема - параметр sniffing - но вы можете научиться исправлять это довольно легко. Это очень хороший компромисс, не так ли?