Несколько уровней агрегации в Power BI: модель отвечает еще быстрее
Агрегации ускоряют модель. Однако агрегированная таблица - это не просто одна таблица, это может быть несколько уровней агрегации. Агрегирование по дате, агрегирование по дате и продукту, агрегирование по дате и продукту и клиенту. Наличие нескольких слоев гарантирует, что у вас всегда будет наилучший возможный результат производительности, и вы будете запрашивать источник данных DirectQuery только для самых элементарных запросов. Давайте посмотрим, как этот процесс возможен и полезен.
Чтобы узнать больше об агрегациях, прочитайте серию статей здесь:
Что такое агрегация в Power BI?
Шаг 1: Создать агрегированную таблицу
Шаг 3. Настройка функций агрегирования
Образец модели
Наша примерная модель данных (которую мы создали в предыдущем посте в блоге) уже имеет агрегированную таблицу; Sales Agg и одну таблицу фактов DirectQuery; FactInternetSales.
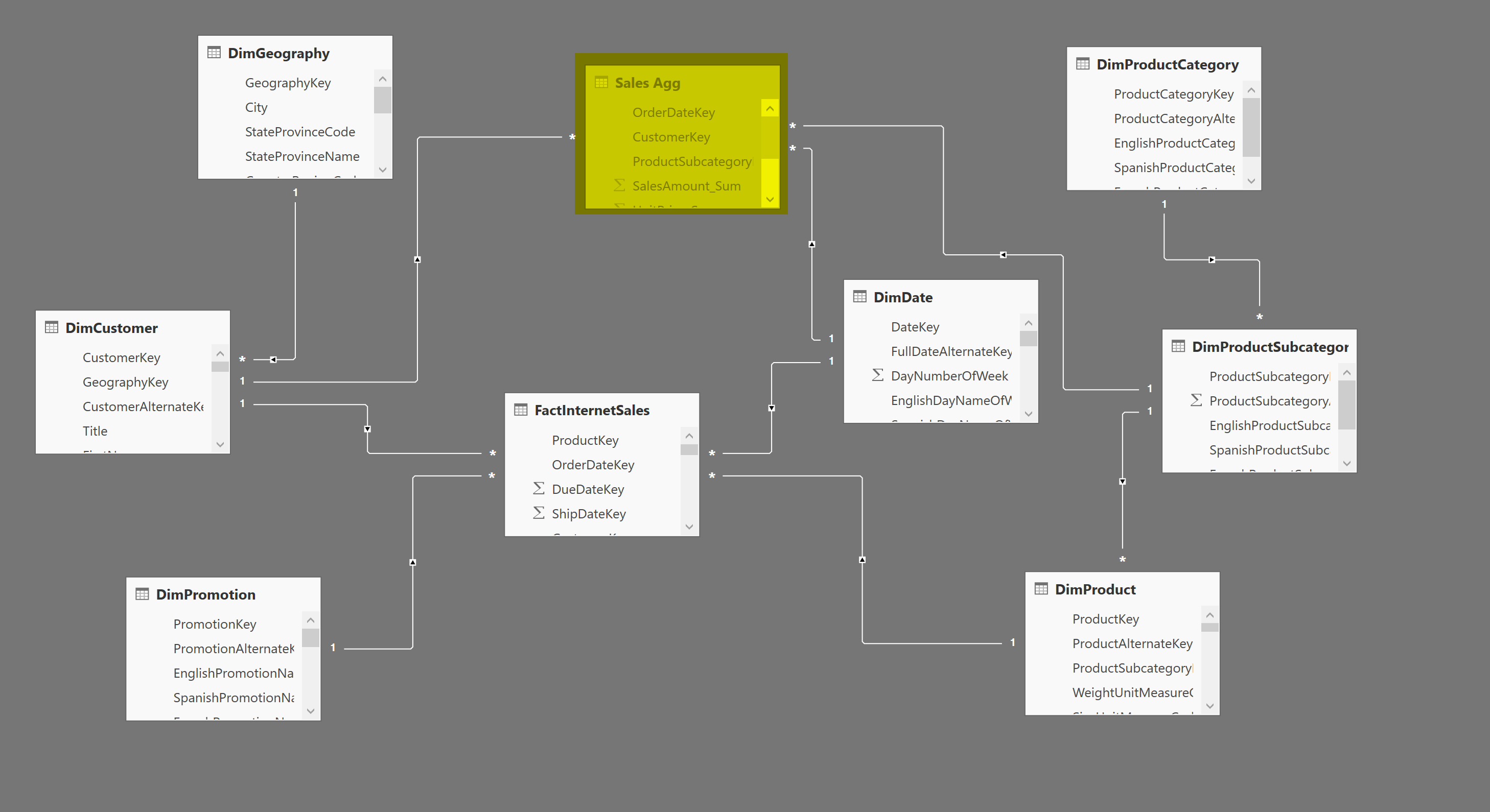
В этом примере мы собираемся добавить больше агрегаций в модель.
Второй уровень агрегации
Создайте таблицу агрегации
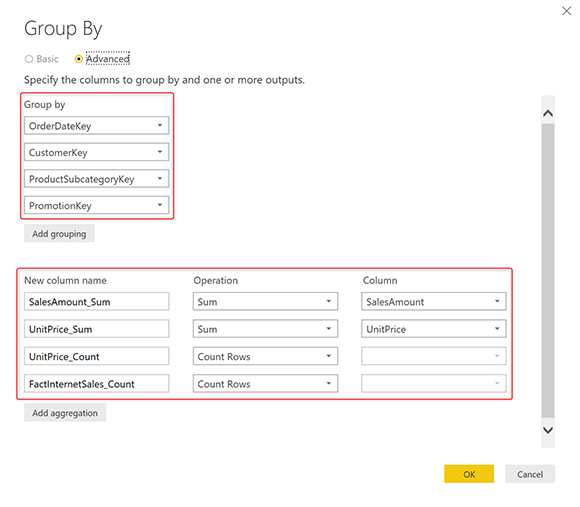
Второй уровень агрегации, который мы собираемся добавить в этом примере, включает в себя также Promotion в качестве параметра группировки. Вот группа по настройкам для нашей второй таблицы агрегирования в Power Query. Если вам интересно узнать подробнее, как можно создать агрегированную таблицу, прочитайте эту статью в блоге о создании агрегированной таблицы.
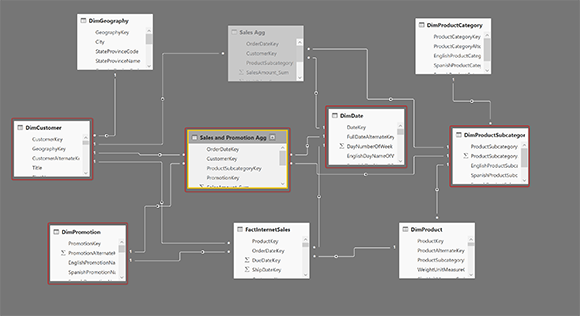
Установите связи
Затем загрузите таблицу в Power BI и создайте связи с DimDate, DimCustomer, DimProductSubcategory и DimPromotion.
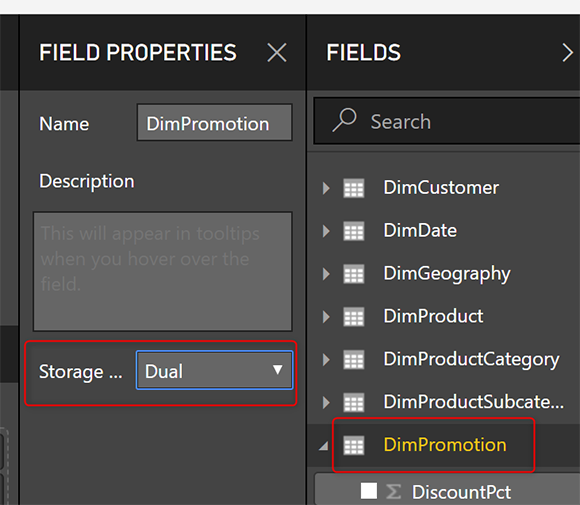
Режим двойного хранения
Установите режим хранения DimPromotion на Dual. Очень важно использовать режим Dual storage. При такой настройке Power BI для анализа на основе агрегации будет использовать копию DimPromition в памяти, а для атомарных уровней транзакций - ее версию DirectQuery. Прочитайте этот пост, чтобы узнать все о режиме двойного хранения.
Управление агрегациями
После настройки отношений и режимов хранения вам необходимо управлять агрегациями в таблице Agg Sales and Promotion (это наша вторая таблица агрегации);
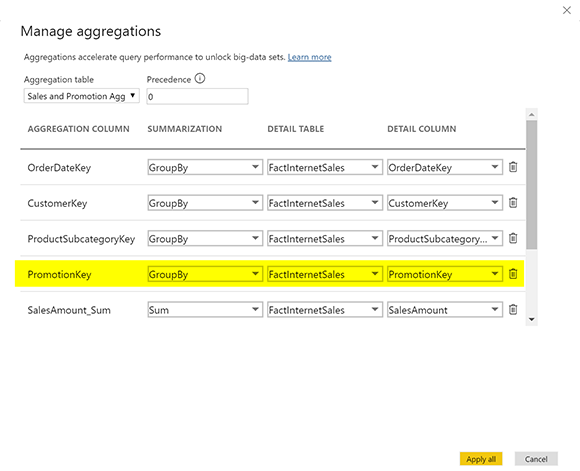
Все очень похоже на настройку агрегации, которую мы использовали ранее для таблицы Sales Agg. Для этого единственным дополнением является действие Group By на PromotionKey.
Настройка приоритета
Когда у вас есть несколько уровней агрегации, вы должны настроить их приоритет. Агрегированная таблица, которая для вас предпочтительна по первенству, должна иметь наивысший приоритет. В этом случае для Sales Agg это может быть 1, а для Sales and Promotion - 0.
Тестирование результата
С помощью описанной выше настройки вы можете иметь визуализации, в которых используются рекламные акции, а также Customer, Date и ProductSubcategory и которые все еще будут получены из агрегации. Вот пример:
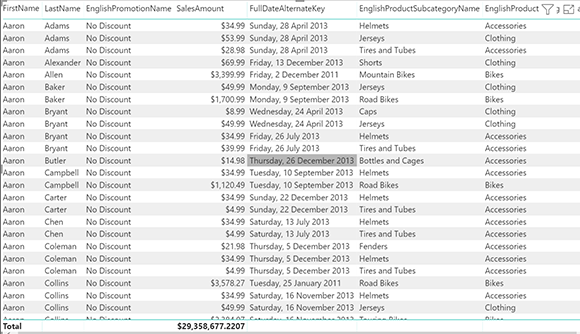
Этот вид визуализации не будет отправлять какие-либо запросы к источнику DirectQuery;
Как насчет приоритета исполнения?
Когда у вас есть несколько уровней агрегации, важно, какой из них запускается первым. В качестве примера, давайте предположим некоторые цифры. Это не реальные цифры, это просто цифры, которые помогут вам понять сценарий. Допустим, большая таблица фактов (FactInternetSales), которая использует режим DirectQuery, содержит 250 миллионов строк. И таблица Agg продаж имеет только 10000 строк. Но у Агента по продажам и продвижению есть 1 000 000 строк. В таком случае, когда вы запрашиваете что-то, на что можно ответить с помощью таблицы с 10K строками (Sales Agg), вы должны это сделать, потому что это будет определенно намного быстрее, чем таблица с миллионом строк (Sales and Promotion Agg). Поэтому нам нужно установить приоритет исполнения. Меньшие таблицы агрегирования должны быть в первую очередь источником анализ
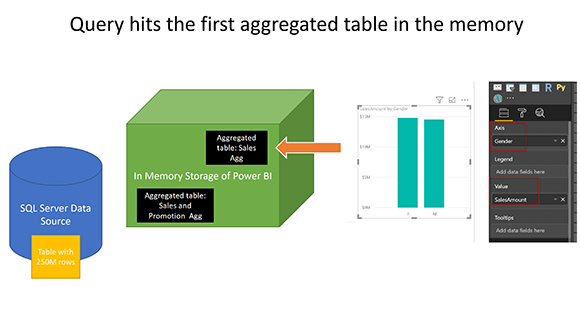
Запрос попадает в первую агрегированную таблицу в памяти
Вот изображение на странице Power BI с использованием Gender (от DimCustomer) и SalesAmount (от FactInternetSales);
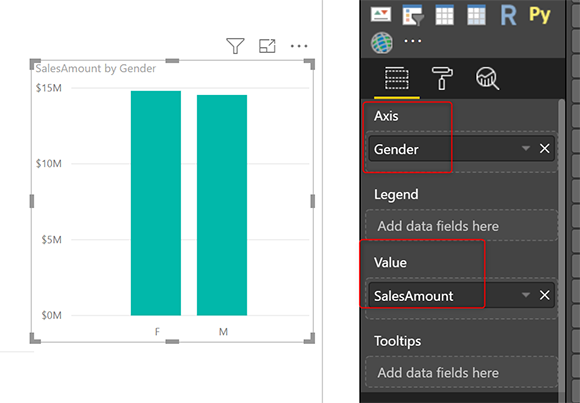
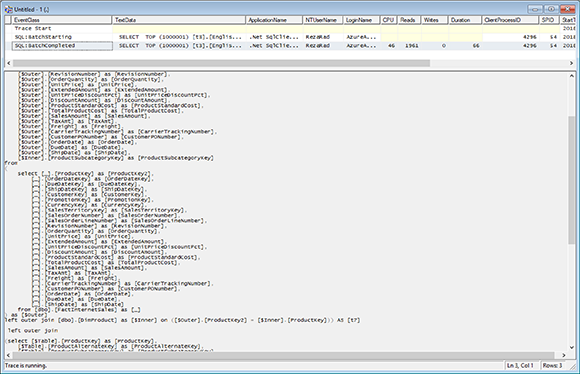
Визуальный элемент, подобный приведенному выше, будет запрашивать не таблицу FactInternetSales, а скрытую агрегированную таблицу. В этом случае он запросит таблицу Sales Agg. Вот скрытый запрос, отправляемый в движок Vertipaq (результат, сгенерированный из SQL Profiler):
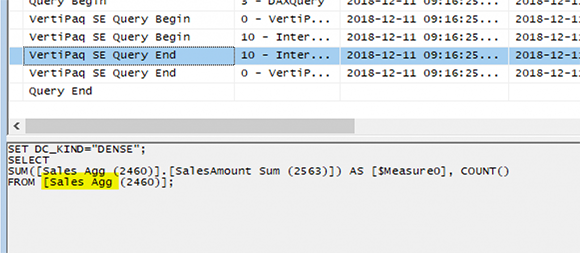
В этом примере; запрос попадает в первую агрегированную таблицу в памяти;
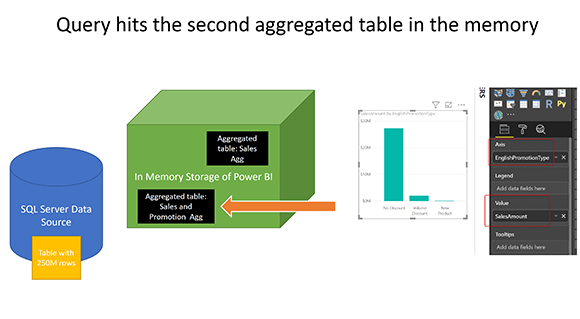
Запрос попадает во вторую агрегированную таблицу в памяти
Вот еще один визуальный элемент, который использует EnglishPromotionType (от DimPromotion) и SalesAmount (от FactInternetSales);
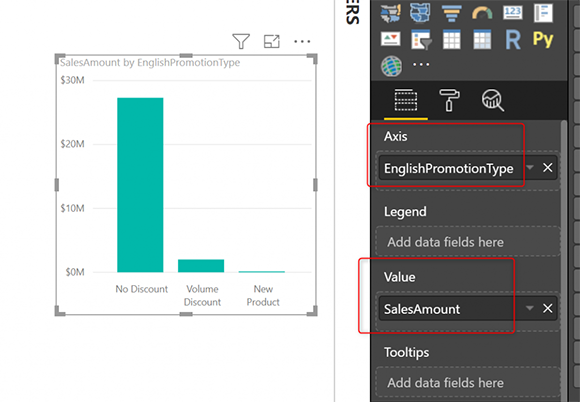
И результат на этот раз не может быть получен из таблицы Sales Agg (потому что DimPromotion не существует как группа по функции), поэтому он будет запрашиваться из второй агрегированной таблицы: Sales and Promotion Agg.
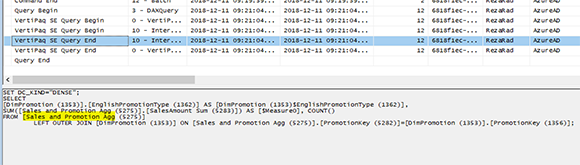
В этом случае запрос попадает во вторую агрегированную таблицу в памяти:
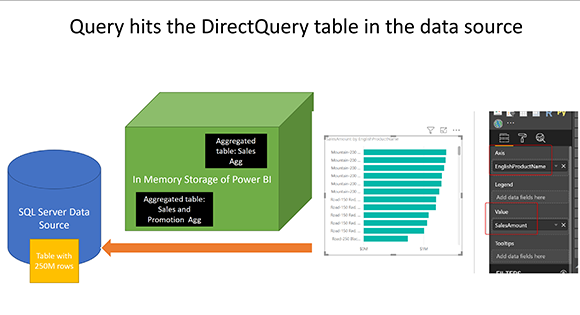
Запрос попадает в таблицу DirectQuery в источнике
В качестве последнего визуального изображения в этом примере ниже используется визуальное описание EnglishProductName (от DimProduct) и SalesAmount (от FactInternetSales);
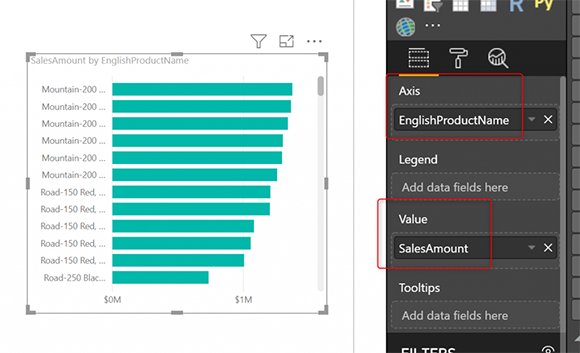
и результат на этот раз не может быть получен ни из одной из агрегированных таблиц, поэтому он приходит непосредственно из исходной таблицы DirectQuery: FactInternetSales
В последнем примере запрос попадает в таблицу DirectQuery в источнике данных:
Power BI прекрасно переключается между слоями агрегированных таблиц, и вы не замечаете этого. Все вышеперечисленные операции происходят скрыто. У пользователя будет только ощущение, что одна таблица (FactInternetSales) обслуживает все запросы, и время ответа на запрос будет очень быстрым (с помощью агрегатов).
Резюме
Агрегация может быть реализована на нескольких уровнях, чтобы максимально ускорить производительность. Если существует определенная комбинация полей измерений, которые пользователи часто использовали в визуализациях, эта комбинация является хорошим кандидатом для агрегации. Это зависит от размера таблицы агрегации, приоритет которой должен соблюдаться.