Обзор и примеры типов данных SQL Server Hierarchyid
Проблема
Тип данных hierarchyid, похоже, имеет особый набор функций и вариантов использования, которые отличаются от других типов данных SQL Server. Поскольку не все часто работают с иерархическими данными, они могут не знать, как извлечь выгоду из типа данных.
Решение
Администраторы и разработчики баз данных SQL Server реже сталкиваются с иерархическими данными, чем реляционные данные. Тем не менее, существует несколько типов данных, которые поддаются иерархическому представлению.
Вы можете представить иерархию как совокупность узлов, в которых узлы связаны друг с другом через ссылки в древовидной структуре. Узел - это элемент дерева, и он может быть представлен строкой со значением иерархии в таблице SQL Server. Любой дочерний узел может иметь только один родительский узел, но каждый родительский узел может иметь один или несколько дочерних узлов. Внутри иерархии есть уровни родителей от родительского элемента верхнего уровня, который имеет первый набор дочерних узлов, от дочерних элементов этих дочерних узлов вплоть до последнего поколения детей, которые не служат родителями для нового поколения дочерних узлов. Дочерние узлы от любого родителя в иерархии могут иметь порядок слева направо, в котором некоторые узлы принадлежат другим узлам. Иерархическая модель данных специально предназначена для вариантов использования со слоями отношений один-ко-многим между ее узлами, а также порядками слева направо для узлов родителя.
Тип данных hierarchyid специально спроектирован для облегчения представления и запроса иерархических данных, таких как географические данные, подобные тем, которые упоминаются в этом совете. Тип данных hierarchyid имеет особый способ представления отношений между узлами в иерархии сверху вниз и слева направо среди дочерних узлов родительского узла. hierarchyid отличается от других типов данных SQL Server тем, что у него есть свойства и методы.
Этот совет представляет собой первоначальный взнос к набору советов из нескольких частей по иерархическим данным и типу иерархической информации в SQL Server. В этом совете вы узнаете несколько различных способов заполнения иерархии с иерархическим типом данных. Вы также получите некоторое представление о подмножестве методов иерархического типа данных.
Иерархический набор данных географических названий
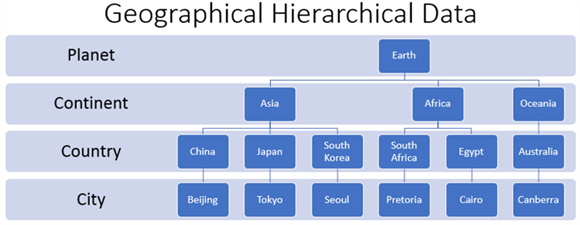
Следующая таблица отображает иерархическое отношение Земли к некоторым ее континентам. Эти континенты показывают некоторые из стран в них, и каждая страна показывает столицу в пределах страны. Хотя имена на диаграмме представляют только подмножество континентов, стран и городов на Земле, этих имен достаточно, чтобы проиллюстрировать основы иерархического набора данных.
- Узел для Земли в верхней части диаграммы является корневым или родительским узлом верхнего уровня иерархического набора данных.
- Три последовательных набора узлов появляются под узлом Земли. Вы можете думать об этих последовательных коллекциях как об иерархических уровнях.
- Первый иерархический уровень предназначен для совокупности континентов. На схеме ниже показаны три континента.
- Ниже коллекции континентов находится еще один иерархический уровень для стран внутри континента.
- Ниже коллекции страны находится окончательный иерархический уровень для городов внутри страны. Города, перечисленные на диаграмме, являются просто национальными столицами.
Иерархические узлы и уровни
Существует два способа представления узлов с иерархическим типом данных. Первый способ - строки, представляющие положение узла на каждом уровне иерархии. Второй способ - с битовыми строками, которые слабо соответствуют шестнадцатеричным значениям. Этот совет дает вам возможность использовать оба способа представления узлов. Последовательности шестнадцатеричных значений и строковые символы являются двумя эквивалентными способами назначения значений идентификаторов узлам.
Строка для представления корневого узла в иерархии - это /. Эта строка соответствует шестнадцатеричному значению 0x в SQL Server. В контексте диаграммы выше, корневой узел обозначает Землю в верхней части диаграммы. Номер уровня корневого узла равен 0.
Строка для представления первой коллекции узлов под корнем - /position_within_first_level /. Слева направо, узлы, расположенные непосредственно под корневым узлом, могут быть представлены как /1/, /2/, /3/. Уровень для сбора узлов ниже корневого уровня равен 1.
- /1/ указывает на Азию.
- /2/ указывает на Африку.
- /3/ указывает на Океанию.
Строка для представления второй коллекции узлов под корнем - /position_within_first_level / position_within_second_level/. Поэтому узлы для географических названий из Китая через Австралию могут быть представлены следующими строками: /1/1/, /1/2/, /1/3/, /2/1/, /2/2 /, /3 /1/. Идентификаторы символьных узлов: /1/1/ для Китая, /1/2 / для Японии и т. д. через /3/1 / для Австралии, самой большой суши на океаническом континенте. Уровень для этой коллекции узлов равен 2.
Строка для представления третьего набора узлов ниже корня - /position_within_first_level / position_within_second_level / position_within_third_level /. Эта коллекция узлов указывает на столицу в каждой стране. Уровень для этой коллекции узлов равен 3.
- Значения символов для столиц в Азии: /1/1/1/, /1/2/1/, /1/3/1. Эти символы соответственно для Пекина, Токио и Сеула.
- Символы для столиц в Африке: /2/1/1 / и /2/2/1. Эти символы, соответственно, для Претории и Каира.
- Символом столицы Австралии в Океании является /3/1/1 /. Этот символ для Канберры.
Вставка иерархических данных в таблицу SQL и отображение данных
Следующий скрипт создает новую версию таблицы с именем SimpleDemo, которая имеет три столбца с именами Node, Geographic Name и Geographic Type. Node предназначен для идентификатора иерархического узла с типом данных иерархии, Geographic Name - для названия географической единицы, такой как Азия или Китай, а Geographic Type - для географического типа, которому принадлежит имя, например, континент для Азии. Ни один из столбцов не имеет индексов, но для столбцов Node и Geographic Name не существует ограничений NULL; другими словами, все строки должны иметь значения Node и Geographic Name, но значения Geographic Type являются необязательными. Хорошее практическое правило заключается в том, что столбцы со значениями иерархии никогда не должны принимать значения NULL, поскольку узлы с нулевым значением не связаны известным образом с другими узлами в иерархическом наборе данных.
Оператор вставки заполняет таблицу SimpleDemo значениями строк. Код определяет три входных значения для каждой строки. Вы можете изучить входные значения для столбца Node, чтобы подтвердить порядок указания строк в иерархическом формате. Формат ввода для узла зависит от формата косой черты, обозначающего уровни в иерархии. Хотя значения можно вводить в формате косой черты для идентификатора узла, они сохраняются в SQL Server в виде битовых строк и отображаются в виде шестнадцатеричных значений при их отображении.
Обратите внимание, что значения для строк не отображаются в иерархическом порядке на уровне в инструкции вставки. Например, строки для географических названий второго уровня появляются перед именами первого уровня. Кроме того, имя корневого уровня отображается последним, а не первым. Ввод значений строки из иерархической последовательности облегчает выделение влияния выбора строк для отображения с предложением и без него по предложению на основе значений узла.
Оператор select в конце скрипта отображает строки в таблице SimpleDemo без условия order by. Строки отображаются в порядке по умолчанию, в котором SQL Server сохраняет строки во время ввода данных. Список выбора содержит элементы для входных столбцов, а также два других элемента, полученных из вызовов метода иерархического типа данных (Node Text и Node Level). В приведенном ниже сценарии вызовы метода позволяют выводить пять столбцов, хотя в каждой строке вводятся только три столбца.
|
begin try drop table SimpleDemo end try begin catch print 'something went wrong with drop table for SimpleDemo' end catch go
-- create a table with hierarchyid data type column -- and two other columns create table SimpleDemo (Node hierarchyid not null, [Geographical Name] nvarchar(30) not null, [Geographical Type] nvarchar(9) NULL);
insert SimpleDemo values -- second level data ('/1/1/','China','Country') ,('/1/2/','Japan','Country') ,('/1/3/','South Korea','Country') ,('/2/1/','South Africa','Country') ,('/2/2/','Egypt','Country') ,('/3/1/','Australia','Country')
-- first level data ,('/1/','Asia','Continent') ,('/2/','Africa','Continent') ,('/3/','Oceania','Continent')
-- third level data ,('/1/1/1/','Beijing','City') ,('/1/2/1/','Tokyo','City') ,('/1/3/1/','Seoul','City') ,('/2/1/1/','Pretoria','City') ,('/2/2/1/','Cairo','City') ,('/3/1/1/','Canberra','City')
-- root level data ,('/', 'Earth', 'Planet')
-- display without sort order returns -- rows in input order select Node ,Node.ToString() AS [Node Text] ,Node.GetLevel() [Node Level] ,[Geographical Name] ,[Geographical Type] from SimpleDemo |
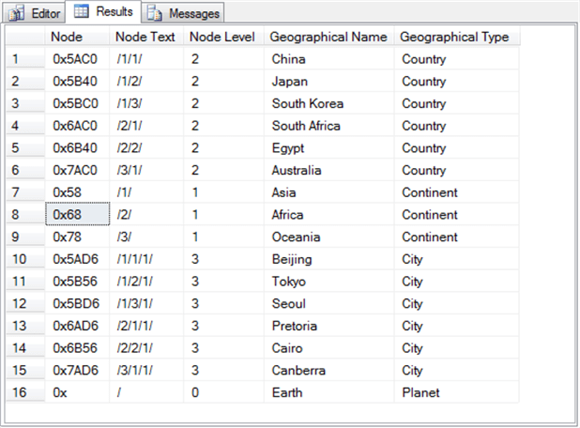
На следующем снимке экрана показана панель Results, заполненная предыдущим сценарием.
- Значения столбца Node отображаются в виде шестнадцатеричных значений, хотя изначально они были введены в формате косой черты, обозначающем идентификаторы узла. SQL Server автоматически преобразует значения формата косой черты для узлов в значения иерархии, которые отображаются в виде шестнадцатеричных значений. SQL Server отображает шестнадцатеричные значения с начальным префиксом 0x. После префикса 0x каждая шестнадцатеричная цифра обозначается символом в диапазоне от 0 до F для целых значений от 0 до 15.
- Столбец Node Text соответствует выводу метода ToString для столбца Node. Метод ToString преобразует значение базовой битовой строки в идентификатор формата косой черты в иерархии.
- Столбец Node Level отображает выходные данные метода GetLevel для значения данных иерархии узла. В контексте этого совета эти значения столбца равны 0 для корневого узла, 1 для узлов первого уровня (континенты), 2 для узлов второго уровня (страны) и 3 для узлов третьего уровня (города).
- Значения столбцов Geographical Name и Geographical Type соответствуют записям в инструкции вставки для каждой строки.
Управление порядком отображения значений иерархии с помощью условия order by
Существует два распространенных способа отображения иерархических данных. Первый называется отображением узлов в глубину, а второй способ называется отображением узлов в ширину. В SQL Server узлы представлены строками в таблице.
- Режим отображения в глубину показывает строки от начального узла, который иногда, но не обязательно, является корневым узлом, до самого нижнего уровня узла в пути в иерархии. Этот процесс повторяется для стольких различных начальных узлов, сколько существует в иерархии.
- Узел в ширину отображает все узлы на одном уровне, прежде чем показывать узлы следующего уровня. Опять же, этот процесс повторяется итеративно для стольких различных уровней узлов, сколько существует в наборе результатов.
Один из подходов к получению списка строк в иерархическом результирующем порядке в порядке глубины заключается в добавлении предложения по условию для Node Text или Node к оператору select в конце предыдущего сценария. Следующий скрипт показывает пример синтаксиса.
|
-- sort by Node Text or Node to get depth-first order of nodes select Node ,Node.ToString() AS [Node Text] ,Node.GetLevel() [Node Level] ,[Geographical Name] ,[Geographical Type] from SimpleDemo order by [Node Text] -- order by Node Text or Node to get depth-first list |
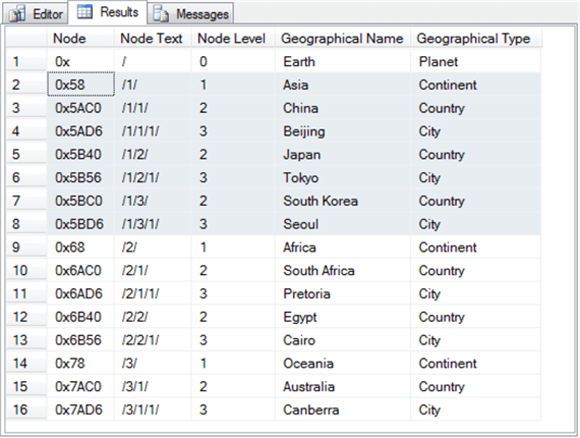
Вот результирующий набор из первого в глубину списка строк результирующего набора, упорядоченного по Node Text.
- Строки со 2 по 8 выделены. Все эти строки для географических названий, относящихся к Азии. Первая строка в наборе имеет идентификатор узла текста /1/, что для континента Азии. Каждая последующая строка в наборе начинается с /1/. Некоторые из последовательных строк относятся к таким странам, как Китай (/1/1/), Япония (/1/2/) и Южная Корея (/1/3/). Остальные строки в выделенном наборе предназначены для таких городов, как Пекин (/1/1/1/), Токио (/1/2/1/) и Сеул (/1/3/1/).
- Строки с 9 по 13 предназначены для географических названий, связанных с африканским континентом. Все эти строки начинаются с идентификатора континента /2/. Строки с 10 по 13 различаются в зависимости от страны и города.
- Строки с 14 по 16 предназначены для географических названий, связанных с Океанией.
Вот подход к генерации списка строк в ширину. В этом случае сортировка осуществляется по уровню узла. В результате этого порядка сортировки строки, список организован по уровню узла вместо текста узла (или узла).
|
-- sort by Node Level to get breadth-first order of nodes select Node ,Node.ToString() AS [Node Text] ,Node.GetLevel() [Node Level] ,[Geographical Name] ,[Geographical Type] from SimpleDemo order by [Node Level] -- order by Node Level gets breadth-first list |
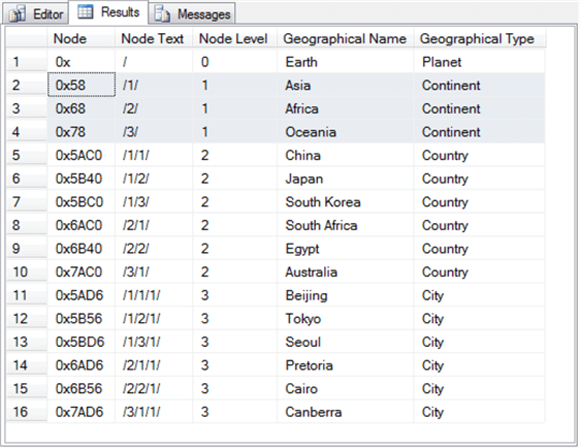
Вот набор результатов из списка строк в ширину. Предыдущий список строк по глубине и следующий список строк по ширине начинаются с корневого ряда для Земли. Однако после первой строки строки появляются в разных порядках.
- Строки со 2 по 4 относятся к трем континентам в наборе результатов: Азия (/ 1 /), Африка (/ 2 /) и Океания (/ 3 /).
- Ряды с 5 по 10 предназначены для всех стран. Названия стран начинаются с Китая (/ 1/1 /) в строке 5 и проходят через Австралию (/ 3/1 /) в строках 10.
- Остальные строки все для городов.
Строки вводятся в порядке слева направо в пределах уровней. Однако, если это не так в наборе данных, который вы используете, и вам нужен вывод в порядке слева направо в пределах уровня, тогда используйте сначала строки [Node Level], а затем Node.
Управление порядком отображения значений иерархии с помощью первичных ключей и некластеризованных индексов
Вместо использования условий order by без индексов для управления позиционированием строки результирующего набора вы можете указать либо столбец Node в качестве первичного ключа для списка результирующих наборов “в глубину”, либо добавить некластеризованный индекс для столбца уровня узла для список результатов “в ширину”. Управляя порядком отображения с помощью первичного ключа или некластеризованного индекса, код отображения может выполняться быстрее. Очевидно, что стоимость запроса для дисплеев обходится дороже, если для управления порядком строк в результирующем наборе используется условие order by без индексов вместо индекса.
Следующий скрипт состоит из двух частей, разделенных линией маркеров комментариев (тире).
- Верхняя часть предназначена для генерации списка строк в глубину с помощью условия order by с просмотром таблицы (без индекса).
- Вторая часть имеет два утверждения.
- Первый оператор является оператором alter table для добавления первичного ключа в таблицу SimpleDemo на основе столбца Node; основной создает кластеризованный индекс на основе узла для таблицы SimpleDemo.
- Затем второй оператор является оператором select, который неявно использует первичный ключ для генерации первого порядка глубины строк.
|
-- sort by Node Text or Node to get depth-first order of nodes select Node ,Node.ToString() AS [Node Text] ,Node.GetLevel() [Node Level] ,[Geographical Name] ,[Geographical Type] from SimpleDemo order by [Node Text] -- order by Node Text or Node to get depth-first list
----------------------------------------------------------------------------------
alter table SimpleDemo add constraint pk primary key (Node);
-- display without sort order -- but with primary key for Node -- returns rows in depth-first order select Node ,Node.ToString() AS [Node Text] ,Node.GetLevel() [Node Level] ,[Geographical Name] ,[Geographical Type] from SimpleDemo |
Прежде чем рассматривать результаты по частям, давайте рассмотрим планы запросов для каждой части, а также связанные с ними затраты на пакетные запросы.
На рисунке ниже показан план запроса для первой части. Обратите внимание, что в плане запроса есть четыре операции, и одна из них с самыми дорогими затратами предназначена для операции сортировки, которая соответствует выполнению заказа по предложению. Кроме того, план запроса начинается с сканирования таблицы, которая также не известна как быстрая.

Следующее изображение предназначено для плана запроса, связанного с оператором выбора во второй части. Оператор select не включает условие order by. Строки набора результатов из оператора select упорядочены неявно в соответствии с кластеризованным индексом, связанным с настройкой первичного ключа pk для столбца Node. SQL Server назначает значения столбцов Node на основе иерархии в глубину. Следовательно, запрос возвращает строки в порядке глубины без необходимости в выражении order by. В результате стоимость этого запроса для этого второго оператора выбора значительно меньше, чем для первого. Стоимость пакетного запроса для второго оператора выбора более чем на семьдесят пять процентов меньше, чем стоимость пакетного запроса для первого оператора выбора!

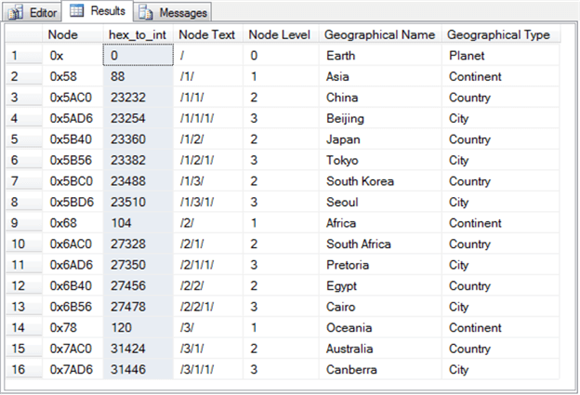
Следующий запрос преобразует шестнадцатеричное значение Node в значение int в столбце hex_to_int. Условие order by размещает строки в порядке глубины, вне зависимости от надлежащим образом заданного первичного ключа. Например, начальное значение уровня узла всегда равно 1 для каждой группы строк, связанных с континентом. Кроме того, преобразованные значения узлов увеличиваются для географических названий, связанных с континентом. Эта последовательность целочисленных значений подтверждает, что узлы перечислены на глубине в пределах
|
-- hex_to_int conversion of Node values -- for order by Node select Node ,convert(INT, convert(varbinary, Node, 1)) hex_to_int ,Node.ToString() AS [Node Text] ,Node.GetLevel() [Node Level] ,[Geographical Name] ,[Geographical Type] from SimpleDemo order by [Node] |
Чтобы воспользоваться некластеризованным индексом для таблицы, столбец, для которого определяется индекс, должен находиться в определении таблицы. Например, чтобы использовать некластеризованный индекс для значений уровня узла в таблице SimpleDemo, в таблице должен быть столбец для значений уровня узла. Это проблема, потому что до этого момента код этой подсказки определял уровень узла в операторе select, а не в таблице SimpleDemo. Следовательно, следующий блок кода повторно задает оператор create table для таблицы SimpleDemo, чтобы включить столбец для уровня узла, а код ниже также заполняет столбец уровня узла из значений в последовательных строках, используемых в его операторе вставки. Вот код для выполнения этих двух задач.
|
-- assign a primary key to hierarchyid column -- in table to get a depth first display by default begin try drop table SimpleDemo end try begin catch print 'something may have gone wrong with drop table for SimpleDemo' end catch go
-- create a table with Node hierarchyid data type column -- (primary key)l also add a Node Level column create table SimpleDemo (Node hierarchyid primary key clustered not null, [Node Level] int not null, [Geographical Name] nvarchar(30) not null, [Geographical Type] nvarchar(9) null);
-- insert data out of order by Node Level, but in -- order by Node insert SimpleDemo values -- second level data ('/1/1/',2,'China','Country') ,('/1/2/',2,'Japan','Country') ,('/1/3/',2,'South Korea','Country') ,('/2/1/',2,'South Africa','Country') ,('/2/2/',2,'Egypt','Country') ,('/3/1/',2,'Australia','Country')
-- first level data ,('/1/',1,'Asia','Continent') ,('/2/',1,'Africa','Continent') ,('/3/',1,'Oceania','Continent')
-- third level data ,('/1/1/1/',3,'Beijing','City') ,('/1/2/1/',3,'Tokyo','City') ,('/1/3/1/',3,'Seoul','City') ,('/2/1/1/',3,'Pretoria','City') ,('/2/2/1/',3,'Cairo','City') ,('/3/1/1/',3,'Canberra','City')
-- root level data ,('/',0,'Earth', 'Planet') |
Следующий блок скрипта состоит из двух частей.
- Первая часть предназначена для оператора select, который генерирует список строк в таблице SimpleDemo в ширину без использования некластеризованного индекса.
- Вторая часть имеет две строки кода.
- Первый оператор T-SQL создает уникальный некластеризованный индекс с именем bfs_index для таблицы SimpleDemo в столбцах Node Level и Node в таблице. Оба столбца являются обязательными, поскольку Node однозначно определяет строки в таблице, но этот код стремится индексировать строки по значениям уровня узла.
- Второй оператор T-SQL является копией оператора выбора из предыдущей части. Однако этот экземпляр оператора select использует преимущества bfs_index.
|
-- this query before the creation of the non-clustered -- index on [Node Level] takes 25 percent of total query cost -- the order by clause overrides the primary key to control row order select Node ,Node.ToString() AS [Node Text] ,[Node Level] ,[Geographical Name] ,[Geographical Type] from SimpleDemo order by [Node Level]
--------------------------------------------------------------------
-- query to compute unique non-clustered index on [Node Level] and Node create unique index bfs_index on SimpleDemo ([Node Level], Node);
-- this is the same query computed after the creation of the -- non-clustered index on [Node Level] and Node; -- this query takes just 15% of total query cost select Node ,Node.ToString() AS [Node Text] ,[Node Level] ,[Geographical Name] ,[Geographical Type] from SimpleDemo order by [Node Level] |
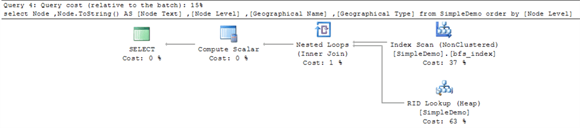
Синтаксис для операторов select в первой и второй частях идентичен, и их вывод также одинаков - а именно упорядоченный список строк в ширину из таблицы SimpleDemo. Основное различие между операторами select заключается не в выходных данных, а в плане запроса для каждого оператора select.
Вот план запроса для первой части. Этот план запроса имеет оператор сортировки, который вносит семьдесят восемь процентов стоимости пакета запроса. Кроме того, сканирование таблицы вносит еще двадцать два процента в стоимость запроса для пакета. Стоимость запроса для пакета составляет двадцать пять процентов.

Вот план запроса для оператора select во второй части. Важно отметить, что план запроса не имеет оператора сортировки. Вместо этого этот план запроса опирается на оператор сканирования индекса для bfs_index. Оператор вложенных циклов объединяет результаты оператора сканирования индекса для bfs_index и поиска RID для кучи таблицы SimpleDemo. Из-за зависимости пакета от bfs_index общая стоимость запроса для оператора select во второй части составляет всего пятнадцать процентов, что на сорок процентов меньше общей стоимости запроса для оператора select в первой части.
Указание новых значений строк с помощью метода hierarchyid
До этого момента этот совет демонстрировал один подход к вставке строк в таблицу со значениями типа данных hierarchyid. Предыдущий подход использует оператор вставки с предложением значений для указания новых значений данных hierarchyid через косые черты и идентификаторы уровня. Однако предыдущий подход не использует преимущества встроенных методов для типа данных hierarchyid. В этом разделе описываются возможности метода GetDescendant для добавления новых строк в таблицу значений данных hierarchyid без использования слеша и идентификаторов уровня. Метод GetDescendant облегчает позиционирование новых узлов в иерархии с точки зрения глубины, ширины и слева направо.
Прежде чем углубиться в синтаксис метода и пример кода, может быть полезно указать, что имя метода GetDescendant, наряду с другими методами типа данных иерархии, чувствительно к регистру. Другими словами, вы можете генерировать ошибки, ссылаясь на метод в коде с такими именами, как GETDESCENDANT, getdescendant или Getdescendant. Единственное допустимое имя: GetDescendant.
В этом разделе показано, как использовать метод GetDescendant для добавления географических имен в таблицу SimpleDemo, созданную и заполненную в разделе «Controlling the display order of hierarchyid values with primary keys and non-clustered indexes». Этот метод будет использоваться для создания новой иерархической ветви, начиная с первого уровня ниже корневого узла. Для метода GetDescendant требуется родительский узел и до двух дочерних узлов, чтобы указать значение иерархии для нового узла в наборе иерархических данных. Синтаксис метода с сайта Microsoft SQL Docs следующий: parent.GetDescendant (child1, child2).
- У родительского узла есть значение hierarchyid, которое меньше значения hierarchyid нового узла, который будет вставлен в иерархию. Значения hierarchyid узлов увеличиваются в ветви, когда вы пересекаете ветку от ее верхнего узла к ее нижнему узлу. Возвращаемое значение GetDescendant представляет собой значение hierarchyid, которое указывает положение нового узла, данного его родительского узла, и любых других ранее указанных дочерних узлов для родителя. С точки зрения глубины вы можете думать о его работе таким образом.
- Если значение hierarchyid parent равно нулю, то метод GetDescendant возвращает нулевое значение.
- Если значение hierarchyid родительского элемента не равно нулю, то метод GetDescendant возвращает ненулевое значение hierarchyid, которое находится на один уровень иерархии ниже уровня родителя. Напомним, что значения уровня на дочернем узле больше, чем на родительском. Корневой узел в верхней части иерархии имеет нулевое значение уровня.
- Значения иерархии child1 и child2 позволяют указать положение нового узла слева направо на иерархическом уровне.
- Если child1 и child2 оба равны NULL, то новый узел является единственным потомком родителя. Значение иерархии нового узла указывает на один уровень ниже уровня для родителя.
- Если child1 не равен нулю, а child2 равен, то значение иерархии нового узла больше, чем child1 и указывает на один уровень ниже уровня родителя.
- Если child1 равен нулю, а child2 не равен нулю, то новый узел получает значение иерархии меньше, чем child2, и указывает на один уровень ниже значения иерархии родителя.
- Если оба child1 и child2 не равны NULL, то новый узел получает значение иерархии между значениями иерархии для child1 и child2 и указывает на один уровень ниже значения иерархии родителя.
Метод GetDescendant также имеет значение, поскольку он перехватывает недопустимые значения иерархии узла parent, child1 и child2 и вызывает исключение.
- Например, если либо child1, либо child2 имеют значение иерархии, указывающее на уровень, отличный от уровня ниже уровня родителя, возникает исключение.
- Этот метод также вызывает исключение, когда значение иерархии для child1 больше или равно значению иерархии для child2.
GetRoot - это еще один метод типа данных иерархии, который можно использовать при указании значений hierarchyid для новых узлов, которые находятся на один уровень ниже корневого узла в иерархии. Метод GetRoot возвращает значение hierarchyid для узла верхнего уровня в иерархии. Узел верхнего уровня обычно имеет значение иерархии 0x, что метод ToString переводит его значение одиночной косой черты (/); уровень для узла верхнего уровня равен 0. В контексте таблицы SimpleDemo корневой узел соответствует узлу с географическим названием Земли. Синтаксис метода GetRoot отличается от других методов типа данных иерархии. Сайт Microsoft SQL Doc определяет синтаксис следующим образом :ierarchyid :: GetRoot ().
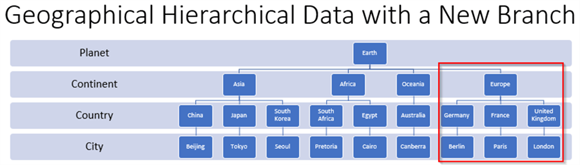
В этом разделе демонстрируется применение методов GetDescendant и GetRoot для добавления ветви из корневого узла для таблицы SimpleDemo. На следующем снимке экрана показана новая ветвь в красном прямоугольнике. Заголовок для всего изображения набора иерархических данных - «Географические иерархические данные с новой ветвью». Сравнивая этот снимок экрана со снимком экрана из раздела «Набор иерархических данных географических имен», вы можете подтвердить, что новая ветвь предназначена для подмножества географических названий, связанных с европейским континентом.
- Следовательно, идентификатор континента для верхнего узла в новой ветви - это Европа. Непосредственно над этим узлом находится корневой узел для всего иерархического набора данных - Земля.
- Одно из трех названий стран идентифицирует каждый из трех дочерних узлов ниже Европы. Идентификаторы узлов слева направо - Германия, Франция и Великобритания.
- Одно из трех названий столиц идентифицирует каждый из узлов под тремя узлами страны.
- Берлин является идентификатором узла столицы под Германией.
- Париж является идентификатором узла столицы ниже Франции.
Лондон является идентификатором узла столицы ниже Соединенного Королевства.
Вот код, использующий методы GetRoot и GetDescendant для добавления узла для Европы в иерархию.
- Код назначает значение иерархии корневого узла локальной переменной @planet.
- Затем значение иерархии для Океании присваивается локальной переменной @last_continent. Напомним, что Океания имеет максимальное значение иерархии среди континентов до тех пор, пока узел Европы не будет добавлен в набор данных.
- Добавление узла для Европы завершается вставкой в оператор.
- Этот оператор в предложении значений присваивает возвращаемое значение GetDescendant со значением родительского иерархии для Земли и значением дочернего иерархии для Океании.
- Уровень для европейского узла равен 1, что на единицу больше, чем значение уровня корневого узла, равное 0.
- Географическое название - это, конечно, Европа, а географический тип - континент.
Расположенный слева направо узел Европы на уровне Continent находится справа от Океании.
|
select *, Node.ToString() [Node String] from SimpleDemo order by [Node Level], Node
-- add new continent (Europe) row after root level declare @planet hierarchyid = hierarchyid::GetRoot() declare @last_continent hierarchyid = (select max(Node) from SimpleDemo where [Geographical Type] = 'Continent') insert into SimpleDemo (Node, [Node Level], [Geographical Name], [Geographical Type]) values (@planet.GetDescendant(@last_continent,null), 1, 'Europe','Continent')
select *, Node.ToString() [Node String] from SimpleDemo order by [Node Level], Node |
Перед двумя операторами объявления и вставкой в оператор следуют операторы выбора.
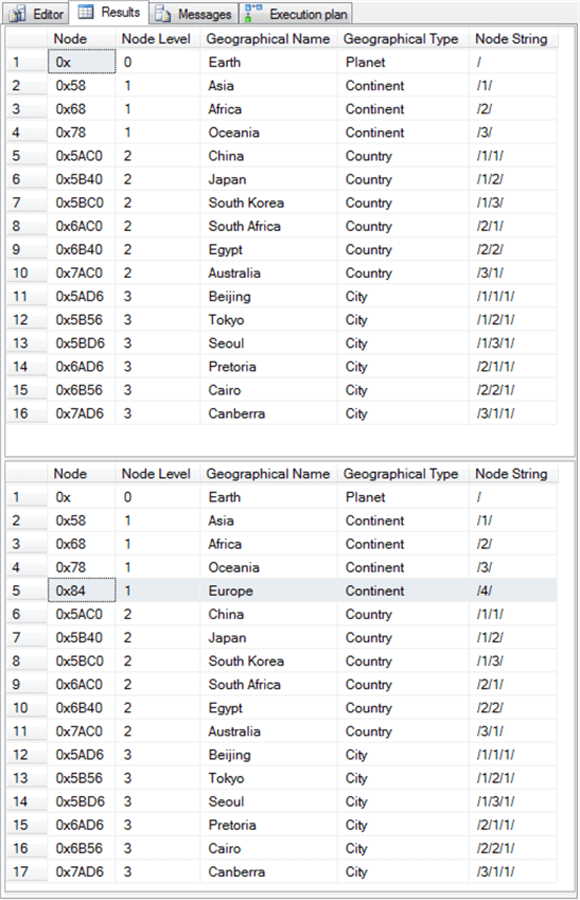
- Предыдущий оператор select отображает строки таблицы SimpleDemo перед добавлением узла Europe. Смотрите первый набор результатов на снимке экрана ниже.
- Следующая инструкция select отображает строки таблицы SimpleDemo после добавления узла Europe. Смотрите второй результат на скриншоте ниже. Узел Европа выделен в строке 5, и в таблице SimpleDemo 17 строк, а не 16 строк в предыдущем наборе результатов.
Следующим шагом в завершении добавления новой ветви в иерархию является добавление узлов для трех европейских стран: Германии, Франции и Великобритании. Следующий сценарий выполняет эту задачу и включает в себя завершающий оператор select, отражающий состояние таблицы SimpleDemo после добавления трех новых узлов стран. Этот скрипт предназначен для запуска в одном пакете, начиная с предыдущего, для добавления узла Европа; это не удастся, если вы запустите его в пакете, отдельном от того, который добавит узел Европа.
Вот краткое изложение того, как работает скрипт.
- Переменная @last_continent была первоначально объявлена в предыдущем скрипте, и вы можете вспомнить, что она указывала на Океанию. При добавлении узлов для каждой из трех стран в новую ветвь родительским узлом является узел Europe. Оператор set переназначает переменную @last_continent в Europe, которая теперь имеет максимальное значение иерархии среди узлов на уровне континента.
- Кроме того, каждый из трех узлов страны имеет настройку уровня иерархии 2. Этот номер уровня указывает на уровень страны в иерархии.
- При добавлении узла для Германии со вставкой в оператор метод GetDescendant имеет родительский узел Europe. И child1, и child2 равны нулю, поскольку в Европе нет дочерних узлов, когда узел Германии добавляется как дочерний узел в узел Europe. Назначения полей Geographical Name и Geographical Type отражают идентификатор узла и имя уровня в иерархии.
- При добавлении узла для Франции локальной переменной @last_country присваивается значение иерархии для узла Германии. @Last_continent остается неизменным с момента установки узла Германии. Затем метод GetDescendant в операторе вставки в оператор добавления узла France использует @last_continent в качестве родительского параметра и @last_country в качестве дочернего параметра. Параметр child2 оставлен нулевым. Эти настройки GetDescendant располагают узел France справа от узла Germany. Назначения полей Geographical Name и Geographical Type отражают идентификатор узла и имя уровня в иерархии.
- При добавлении узла для Соединенного Королевства локальной переменной @last_country переназначается значение иерархии для узла Франция. Затем метод GetDescendant в инструкции вставки в для добавления узла United Kingdom использует @last_continent в качестве родительского параметра и @last_country в качестве дочернего параметра. Параметр child2 оставлен нулевым. Эти настройки GetDescendant располагают узел Соединенного Королевства справа от узла Франция. Назначения полей Geographical Name и Geographical Type отражают идентификатор узла и имя уровня в иерархии.
|
-- add first new country (Germany) row belonging to the new continent set @last_continent = (select max(Node) from SimpleDemo where [Geographical Type] = 'Continent') insert into SimpleDemo (Node, [Node Level], [Geographical Name], [Geographical Type]) values (@last_continent.GetDescendant(null,null), 2, 'Germany','Country')
-- add second new country (France) row belonging to the new continent declare @last_country hierarchyid = (select max(Node) from SimpleDemo where [Geographical Type] = 'Country') insert into SimpleDemo (Node, [Node Level], [Geographical Name], [Geographical Type]) values (@last_continent.GetDescendant(@last_country,null), 2, 'France','Country')
-- add third new country (United Kingdom) row belonging to the new continent set @last_country = (select max(Node) from SimpleDemo where [Geographical Type] = 'Country') insert into SimpleDemo (Node, [Node Level], [Geographical Name], [Geographical Type]) values (@last_continent.GetDescendant(@last_country,null), 2, 'United Kingdom','Country')
select *,Node.ToString() from SimpleDemo order by [Node Level], Node |
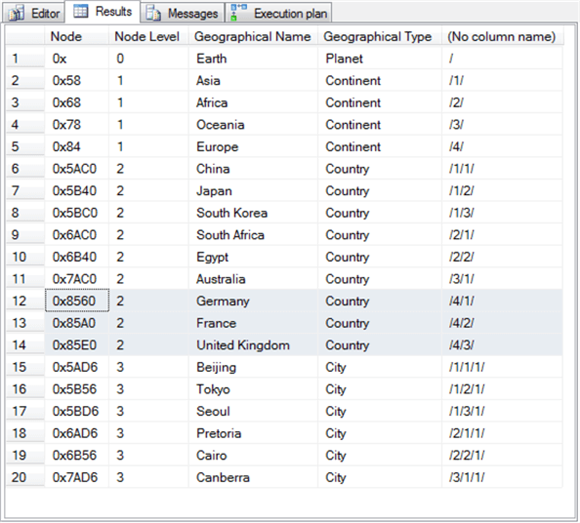
На следующем снимке экрана показан набор результатов из последнего оператора выбора в предыдущем сегменте сценария.
- Обратите внимание, что в таблице SimpleDemo теперь двадцать строк. Это включает одну новую строку для каждого из трех узлов страны.
- Строки для трех новых узлов страны выделены.
Подход для добавления столиц для Германии, Франции и Великобритании немного отличается от подхода для добавления узлов страны к узлу Европы. Он отличается, потому что каждый узел страны имеет только один узел города под ним, тогда как все три узла страны имеют общий родительский узел (Европа). Следующий код работает для добавления к каждому узлу страны дочернего узла со столицей страны. Как и в предыдущих двух сегментах скрипта, этот должен выполняться в одном пакете вместе с предыдущими двумя сегментами кода. Этот код добавляет конечные листья в новую ветвь, и поэтому он зависит от предшествующего существования более ранних узлов в пути ветвления.
Код требует две строки для добавления города в страну.
- Первая строка присваивает значение переменной @country либо с помощью оператора Declare, либо с помощью оператора set после первоначального объявления переменной @country.
- Вторая строка - это вставка в оператор, который ссылается на переменную @country как родительский параметр при вызове метода GetDescendant для задания значения иерархии для нового узла города. Параметры child1 и child2 равны нулю, поскольку в каждой стране есть только одна столица.
Есть несколько других моментов, касающихся вставки в утверждения, которые стоит упомянуть. После создания значения иерархии с помощью метода GetDescendant для каждого города метод вставки в делает еще три назначения.
- Уровню узла присваивается значение 3, которое является последним уровнем в новой ветви. Это назначение одинаково для всех листьев в иерархии.
- Географическое название уровня города отличается для каждой страны. Столица: Берлин для Германии, Париж для Франции, Лондон для Соединенного Королевства
|
-- add new city (Berlin) to country of Germany declare @country hierarchyid = (select node from SimpleDemo where [Geographical Name] = 'Germany') insert into SimpleDemo (Node, [Node Level], [Geographical Name], [Geographical Type]) values (@country.GetDescendant(null,null), 3, 'Berlin', 'City')
-- add new city (Paris) to country of France set @country = (select node from SimpleDemo where [Geographical Name] = 'France') insert into SimpleDemo (Node, [Node Level], [Geographical Name], [Geographical Type]) values (@country.GetDescendant(null,null), 3, 'Paris', 'City')
-- add new city (London) to country of United Kingdom set @country = (select node from SimpleDemo where [Geographical Name] = 'United Kingdom') insert into SimpleDemo (Node, [Node Level], [Geographical Name], [Geographical Type]) values (@country.GetDescendant(null,null), 3, 'London', 'City')
select *,Node.ToString() from SimpleDemo order by [Node Level], Node |
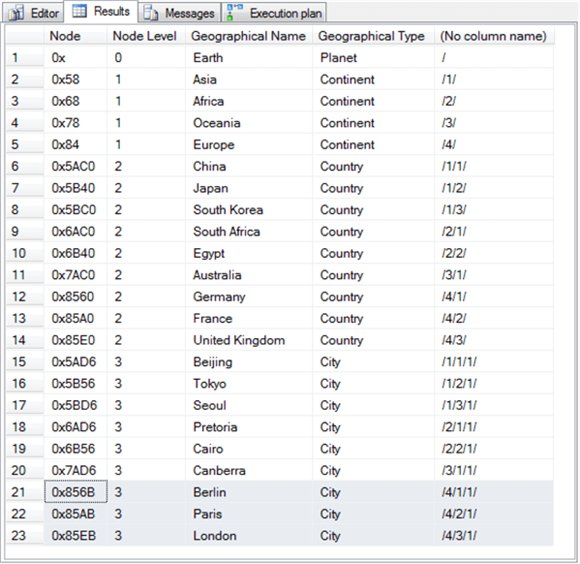
Вот набор результатов из предыдущего сегмента скрипта.
- В этом наборе результатов есть 23 строки.
- Последние 3 строки выделены; эти строки для столиц.
- Всего в этом разделе добавлено семь строк, помимо тех, которые были заполнены в предыдущем разделе для таблицы SimpleDemo.
- Один новый ряд для континента новой ветви.
- Три дополнительные детские строки предназначены для стран на европейском континенте.
- Наконец, три дополнительных дочерних ряда - по одному для каждой страны - предназначены для столиц.
Следующие шаги
- Начните с запуска кода в разделе «Вставка иерархических данных в таблицу SQL и отображение данных». Это познакомит вас с основами вставки иерархических строк набора данных в таблицу SQL Server и отображения строк в таблице.
- Затем запустите код в разделе «Управление порядком отображения значений иерархии с помощью порядка по предложениям», чтобы ознакомиться с распечаткой содержимого иерархических данных в любом порядке по глубине.
- Затем запустите код в разделе «Управление порядком отображения значений иерархии с помощью первичных ключей и некластеризованных индексов», чтобы ознакомиться с тем, как использовать индексы для вывода списка иерархических данных в порядке как по глубине, так и по ширине.
- Наконец, запустите код в разделе «Указание новых значений строк с методами иерархии», чтобы узнать, как использовать метод данных иерархии GetDescendant для программного добавления новых узлов в таблицу значений иерархических данных. Запустите три сегмента сценария из раздела в одном пакете. Если вы решите запустить код более одного раза, вам может быть полезно начать со свежей копии таблицы, созданной и заполненной в разделе «Управление порядком отображения значений иерархии с помощью первичных ключей и некластеризованных индексов».