Согласования имен SQL
Согласования имен SQL для таблиц и всех связанных с ними объектов, таких как индексы, ограничения, ключи и триггеры, важны для совместной работы. Таблицы с плохими именами и другие объекты затрудняют ведение баз данных.
Имена таблиц должны соответствовать правилам для идентификаторов SQL Server и содержать не более 128 символов. Можно заставить SQL Server принимать нестандартные имена таблиц, заключив их в квадратные скобки, но это очень плохая идея, потому что их нужно «цитировать» всякий раз, когда они используются в сценариях.
Временные имена таблиц немного отличаются тем, что они имеют префикс одного знака (#) и имеют длину не более 116 символов. После любого префикса со специальным значением («@» означает переменную таблицы, «#» означает временную таблицу или «##» означает глобальную временную таблицу), первая буква должна быть буквой, определенной стандартом Unicode 3.2. Это означает, что это либо латинский символ от A до Z, прописные или строчные буквы, либо буквенный символ из других языков. Последующие символы могут законно использоваться:
- буквы, как определено в стандарте Unicode 3.2.,
- десятичные числа из базовой латиницы или других национальных сценариев,
- «At» (@), «знак доллара» ($), «число» или «знак хеша» (#)
- Подчеркивание, обычно используемое для представления пробелов, таких как Overdue_Account.
Никогда не используйте пробелы, встроенные символы или зарезервированные имена, потому что они не переносимы, требуют квадратных скобок и могут запутать сценарии и процедуры.
Мы можем очень просто проверить соответствие спецификации идентификаторов SQL Server с помощью следующего SQL.
|
SELECT name FROM sys.objects WHERE name LIKE '%[^_A-Z0-9@$#]%' COLLATE Latin1_General_CI_AI --contains illegal characters OR name NOT LIKE '[A-Z]%' COLLATE Latin1_General_CI_AI --doesn't start with a character |
Мы можем проверить зарезервированные слова в объектах в этом немного громоздком, но эффективном коде
|
SELECT name FROM sys.objects INNER JOIN ( VALUES ('ADD'), ('EXTERNAL'), ('PROCEDURE'), ('ALL'), ('FETCH'), ('PUBLIC'), ('ALTER'), ('FILE'), ('RAISERROR'), ('AND'), ('FILLFACTOR'), ('READ'), ('ANY'), ('FOR'), ('READTEXT'), ('AS'), ('FOREIGN'), ('RECONFIGURE'), ('ASC'), ('FREETEXT'), ('REFERENCES'), ('AUTHORIZATION'), ('FREETEXTTABLE'), ('REPLICATION'), ('BACKUP'), ('FROM'), ('RESTORE'), ('BEGIN'), ('FULL'), ('RESTRICT'), ('BETWEEN'), ('FUNCTION'), ('RETURN'), ('BREAK'), ('GOTO'), ('REVERT'), ('BROWSE'), ('GRANT'), ('REVOKE'), ('BULK'), ('GROUP'), ('RIGHT'), ('BY'), ('HAVING'), ('ROLLBACK'), ('CASCADE'), ('HOLDLOCK'), ('ROWCOUNT'), ('CASE'), ('IDENTITY'), ('ROWGUIDCOL'), ('CHECK'), ('IDENTITY_INSERT'), ('RULE'), ('CHECKPOINT'), ('IDENTITYCOL'), ('SAVE'), ('CLOSE'), ('IF'), ('SCHEMA'), ('CLUSTERED'), ('IN'), ('SECURITYAUDIT'), ('COALESCE'), ('INDEX'), ('SELECT'), ('COLLATE'), ('INNER'), ('SEMANTICKEYPHRASETABLE'), ('COLUMN'), ('INSERT'), ('SEMANTICSIMILARITYDETAILSTABLE'), ('COMMIT'), ('INTERSECT'), ('SEMANTICSIMILARITYTABLE'), ('COMPUTE'), ('INTO'), ('SESSION_USER'), ('CONSTRAINT'), ('IS'), ('SET'), ('CONTAINS'), ('JOIN'), ('SETUSER'), ('CONTAINSTABLE'), ('KEY'), ('SHUTDOWN'), ('CONTINUE'), ('KILL'), ('SOME'), ('CONVERT'), ('LEFT'), ('STATISTICS'), ('CREATE'), ('LIKE'), ('SYSTEM_USER'), ('CROSS'), ('LINENO'), ('TABLE'), ('CURRENT'), ('LOAD'), ('TABLESAMPLE'), ('CURRENT_DATE'), ('MERGE'), ('TEXTSIZE'), ('CURRENT_TIME'), ('NATIONAL'), ('THEN'), ('CURRENT_TIMESTAMP'), ('NOCHECK'), ('TO'), ('CURRENT_USER'), ('NONCLUSTERED'), ('TOP'), ('CURSOR'), ('NOT'), ('TRAN'), ('DATABASE'), ('NULL'), ('TRANSACTION'), ('DBCC'), ('NULLIF'), ('TRIGGER'), ('DEALLOCATE'), ('OF'), ('TRUNCATE'), ('DECLARE'), ('OFF'), ('TRY_CONVERT'), ('DEFAULT'), ('OFFSETS'), ('TSEQUAL'), ('DELETE'), ('ON'), ('UNION'), ('DENY'), ('OPEN'), ('UNIQUE'), ('DESC'), ('OPENDATASOURCE'), ('UNPIVOT'), ('DISK'), ('OPENQUERY'), ('UPDATE'), ('DISTINCT'), ('OPENROWSET'), ('UPDATETEXT'), ('DISTRIBUTED'), ('OPENXML'), ('USE'), ('DOUBLE'), ('OPTION'), ('USER'), ('DROP'), ('OR'), ('VALUES'), ('DUMP'), ('ORDER'), ('VARYING'), ('ELSE'), ('OUTER'), ('VIEW'), ('END'), ('OVER'), ('WAITFOR'), ('ERRLVL'), ('PERCENT'), ('WHEN'), ('ESCAPE'), ('PIVOT'), ('WHERE'), ('EXCEPT'), ('PLAN'), ('WHILE'), ('EXEC'), ('PRECISION'), ('WITH'), ('EXECUTE'), ('PRIMARY'), ('WITHIN GROUP'), ('EXISTS'), ('PRINT'), ('WRITETEXT'), ('EXIT'), ('PROC') ) AS reserved (word) ON reserved.word = sys.objects.name; |
Остерегайтесь чисел в любых именах объектов, особенно имен таблиц. Обычно он отображает неуклюжую денормализацию, когда данные вводятся в имя, как в «Year2017», «Year2018» и т. д. Обычно значение цифр очевидно для исполнителя, но не для тех, кто поддерживает систему.
|
SELECT name FROM sys.tables WHERE name LIKE '%[0-9]%' COLLATE Latin1_General_CI_AI --contains numbers |
Если вы более спокойно относитесь к этому и будете терпеть отдельные числа, но не более, попробуйте это:
|
SELECT name FROM sys.tables WHERE name LIKE '%[0-9][0-9]%' COLLATE Latin1_General_CI_AI –contains more than one adjacent number |
Нет общепринятых стандартов для именования объектов SQL. Хотя ИСО/МЭК 11179 упоминается как стандарт для именования, он фактически устанавливает только стандарт для определения соглашений об именах. В документе «Принципы присвоения имен» есть образец стандарта (ИСО/МЭК 11179-5), но это всего лишь пример того, как следует определять стандарт. Тем не менее, это довольно близко к общей хорошей практике в программировании.
При именовании таблицы рекомендуется использовать собирательное имя или «object class term» для объекта, если такой существует (например, «Сотрудник», «Стоимость», «Дерево», компонент, член, аудитория, персонал или преподавательский состав), но использовать единственное число а не форма множественного числа, где это возможно. В целях обслуживания используйте согласованное соглашение об именах, которое является информативным, но кратким. Это очень помогает начать со словаря правильных существительных и глаголов, связанных с доменом приложения, и использовать его. Если это оказывается недостаточным, то команда может достроить его. Если модель данных была создана как часть фазы проектирования, этот словарь должен быть конечным продуктом этой работы.
Никогда не используйте описательный префикс, такой как tbl_. Эта нотация, обратная венгерской, никогда не была стандартом для SQL и противоречит соглашениям об именах SQL Server. Некоторым системным процедурам и функциям были присвоены префиксы «sp_», «xp_» или «dt_» для обозначения того, что они были «специальными» и их следует сначала найти в базе данных master. Использование tbl_prefix для таблицы, часто называемой «tibbling», пришло из баз данных, импортированных из Access, когда SQL Server был впервые представлен. К сожалению, это было соглашение о доступе, унаследованное от Visual Basic, свободно типизированного языка. Даже если бы префиксы были хорошими, никто не использовал бы «Tbl_» для таблицы. Существуют установленные коды для SQL Server, а код для таблицы - U (очевидно, сокращение от «User Table»). Все еще есть много администраторов баз данных, которые хотят «тиблить», но никогда не возникает сомнений, какой тип объекта находится в SQL Server, если вы знаете его имя, схему и базу данных, потому что его тип есть в sys.objects: очевидно из использования. SQL Server является строго типизированным языком.
|
SELECT name FROM sys.objects WHERE Left(name,3) IN ('tbl','sp_','xp_','dt_') --tibbling! |
Не присваивайте таблице такое же имя, как у одного из ее столбцов.
|
SELECT Thetable.Name FROM sys.columns cols INNER JOIN sys.tables Thetable ON Thetable.object_id = cols.object_id WHERE cols.NAME=Thetable.name |
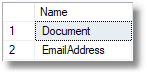
По возможности избегайте объединения двух имен таблиц вместе, чтобы создать имя таблицы отношений, когда в языке уже есть слово для описания отношений. Например используйте Client, а не EmployeeCustomer
Этот код найдет эти таблицы. Не пытайтесь сделать это на огромной базе данных!
|
SELECT name FROM sys.tables AS TheTable INNER JOIN ( SELECT first.name + second.name FROM sys.tables AS first CROSS JOIN (SELECT name FROM sys.tables) AS second ) AS combined(doubleName) ON combined.doubleName = TheTable.name; |
На AdventureWorks2016 вы получите несколько таблиц с более подходящим названием
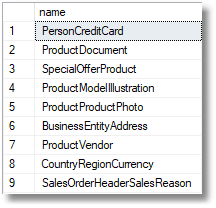
Следите за тем, чтобы имена таблиц были короткими, потому что многие соглашения об именах требуют, чтобы триггеры, ограничения и индексы включали в себя имя используемой таблицы или таблиц. Ограничение внешнего ключа может стать громоздким.
Будьте последовательны в расположении таблиц и использовании подчеркивания для разграничения слов.
Столбец таблицы должен иметь «качество, общее для всех членов класса объекта», и должно иметь имя, которое соответствует тому, как простой язык ссылается на свойство, например First_Name, Amount, Measure, Number, Quantity или Text. Никогда не применяйте коллективное имя к свойству, например, свойство «Employee_name» в таблице Employee. Это обеспечит избыточность, когда в запросе будет указан квалифицированный столбец - Employee.Employee_name.
Вы можете быстро найти все столбцы с избыточностью в их именах, если они обозначены точечной нотацией.
|
SELECT TheTable.name AS TableName, TheColumn.name AS ColumnName FROM sys.tables AS TheTable INNER JOIN sys.columns AS TheColumn ON TheColumn.object_id = TheTable.object_id WHERE TheColumn.name LIKE '%' + TheTable.name + '%'; |
AdventureWorks полна такого рода проблем.
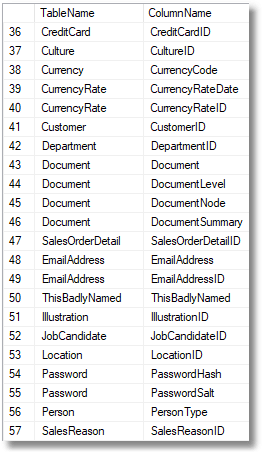
Кто бы ни придумал имя Person.Person.personType, у него не хватало словарного запаса. Это может быть идеей обнаружить еще более гнусное преступление, назвав таблицу так же, как схему!
|
Простое руководство по именованию заключается в уважении идеи SQL как понятного языка, основанного на письменном языке. Это предполагает, что имена функций должны вписываться в семантику предложения SELECT, если у нас есть функция, которая вводит предложение с заглавной буквы, делает первый символ каждого слова длиннее трех символов заглавной буквой (MLA), тогда вы бы назвали его 'заглавной ()'. Процедуры имели бы имена глагол-существительное задач, так как они выполняются.
Процедуры должны следовать соглашению об использовании глагола, популяризованному PowerShell. Очевидно, что стандартные глаголы и существительные будут происходить из процесса проектирования базы данных и модели данных организации или предметной области.
Резюме
В SQL Server есть определенные правила стиля, но их не так много. Более важно быть последовательным и, по возможности, писать так, чтобы это было наиболее близко к стандартному SQL. SQL Server дает вам немного свободы в вашем стиле, но поскольку вы можете делать такие вещи, как ввод чисел, пробелов и управляющих символов в имена, это не значит, что вы должны это делать. Вы можете писать на эксцентричных архаичных диалектах SQL, но вы все еще эксцентричны. В командной работе лучше всего принять определенный стандарт, каким бы абсурдным он ни был, и приложить все усилия, чтобы убедить остальную команду измениться.
SQL отличается от любого другого компьютерного языка тем, что он был спроектирован так, чтобы быть максимально приближенным к человеческому языку, поэтому он может использоваться непрофессионалами для бизнес-анализа. Соглашения об именах должны вписываться в эту основную идею, чтобы код базы данных читался четко с минимальным количеством документации, и у других не возникало трудности в понимании.