Сравнение возможностей SQL Server: десятичный и числовой тип, Timestamp и Rowversion, уникальный индекс и уникальное ограничение
Проблема
В SQL Server есть некоторые понятия, которые имеют разные имена, но функционально они эквивалентны. Однако разница между их именами иногда может сбивать с толку, и поэтому эти вопросы можно классифицировать как часто задаваемые вопросы в сфере SQL Server. В этой статье мы рассмотрим некоторые из этих концепций и выявим их сходства и различия.
Решение
В этой статье мы сформулируем эти часто задаваемые вопросы и дадим объяснения. Итак, давайте начнем с аналогичных типов данных и определим первый вопрос.
В чем разница между десятичными и числовыми типами данных в SQL Server?
Ответ короткий: между ними нет разницы, они абсолютно одинаковые. Оба имеют фиксированную точность и масштабные числа. Для обоих минимальная точность равна 1, а максимальная - 38 (18 - по умолчанию). Оба типа данных охватывают диапазон от -10 ^ 38 + 1 до 10 ^ 38-1. Только их имена разные и не более того. Таким образом, эти типы могут использоваться взаимозаменяемо. В следующем примере показано объявление и использование переменных десятичного и числового типов:
|
DECLARE @numVar NUMERIC (4,2)=16.25 DECLARE @decVar NUMERIC (4,2)=15 SELECT @numVar AS NumericVar, @decVar AS DecimalVar SET @numVar=@decVar SELECT @numVar AS NumericVar, @decVar AS DecimalVar |
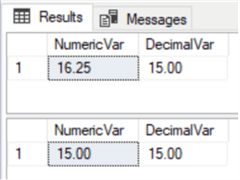
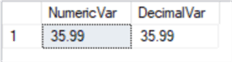
Поскольку они относятся к одним и тем же типам, проблем при назначении десятичных и числовых переменных (с одинаковым масштабом и точностью) не возникало. В следующем примере мы можем видеть, что если мы присваиваем значение с более высокой шкалой, оно округляется:
|
DECLARE @numVar NUMERIC (4,2)=35.98645 DECLARE @decVar NUMERIC (4,2)=35.98645 SELECT @numVar AS NumericVar, @decVar AS DecimalVar |
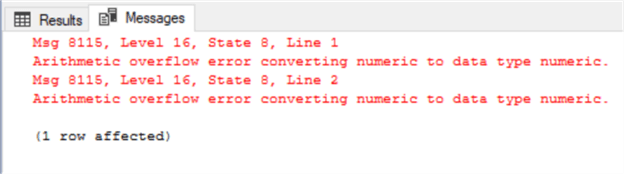
Однако, если точность выше, будет сгенерирована ошибка:
|
DECLARE @numVar NUMERIC (4,2)=355.98645 DECLARE @decVar NUMERIC (4,2)=335.98645 SELECT @numVar AS NumericVar, @decVar AS DecimalVar |
Подводя итог, можно сказать, что десятичные и числовые типы данных идентичны, и разработчики могут свободно пользоваться тем, что они предпочитают.
Каковы различия между типами данных Timestamp и Rowversion SQL Server?
На самом деле, эти типы данных являются синонимами. Объекты этих типов данных содержат автоматически сгенерированные двоичные числа, которые являются уникальными в базе данных. Размер хранилища для этих типов данных составляет 8 байт. В то время как обнуляемый столбец типа данных rowversion (timestamp) семантически эквивалентен столбцу varbinary (8), ненулевой столбец типа rowversion (timestamp) семантически эквивалентен двоичному столбцу (8).
Несмотря на свое название, тип данных timestamp (rowversion) не имеет ничего общего с типами данных date и time. Тип данных Rowversion (timestamp) представляет собой инкрементное число. Каждый раз, когда строка в таблице, содержащей столбец версии строки (отметка времени), вставляется или обновляется, увеличенное значение версии строки базы данных (отметка времени) вставляется в столбец этой строки. Это делает столбец rowversion (timestamp) очень полезным для обнаружения, сравнения и синхронизации изменений данных в таблицах. В каждой таблице может быть не более одного столбца с типом данных rowversion (timestamp).
Чтобы проиллюстрировать эти типы данных на практике, давайте создадим следующие таблицы с типами данных rowversion и timestamp:
|
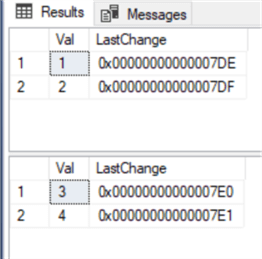
CREATE TABLE ##tmpTableA ( Val INT, LastChange ROWVERSION NOT NULL ) CREATE TABLE ##tmpTableB ( Val INT, LastChange TIMESTAMP NOT NULL ) INSERT INTO ##tmpTableA(Val) VALUES(1),(2) INSERT INTO ##tmpTableB(Val) VALUES(3),(4) SELECT * FROM ##tmpTableA SELECT * FROM ##tmpTableB |
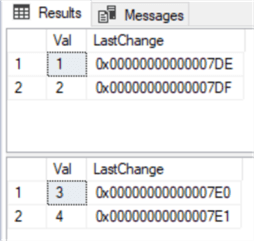
Как видно из обеих таблиц, значения для столбца LastChange были сгенерированы автоматически:
Теперь давайте скопируем эти данные в таблицы, в которых есть столбцы с двоичным (8) типом данных для хранения данных версии строк (timestamp) из таблиц выше:
|
CREATE TABLE ##tmpTableC ( Val INT, LastChange BINARY(8) NOT NULL ) CREATE TABLE ##tmpTableD ( Val INT, LastChange BINARY(8) NOT NULL ) INSERT INTO ##tmpTableC (Val, LastChange) SELECT Val, LastChange FROM ##tmpTableA INSERT INTO ##tmpTableD (Val, LastChange) SELECT Val, LastChange FROM ##tmpTableB SELECT * FROM ##tmpTableC SELECT * FROM ##tmpTableD |
Результат показывает, что данные версии строки (timestamp) успешно копируются в двоичные (8) столбцы, поскольку они семантически эквивалентны:
При этом необходимо учитывать некоторые моменты при работе с этими типами данных:
- Согласно Microsoft, тип данных timestamp устарел и будет удален в будущих версиях. Таким образом, рекомендуется заменить timestamp везде, где это возможно.
- В случае создания таблицы в SQL Server Management Studio и установки типа столбца единственным доступным вариантом является timestamp. В выпадающем списке нет доступных версий строк. Даже если таблица создана с использованием кода T-SQL, а тип столбца определен как преобразование строк, в Management Studio его тип будет отображаться как timestamp.
- В коде T-SQL можно создать столбец с типом timestamp, не упоминая имя столбца. В этом случае автоматически будет сгенерировано имя столбца, который будет называться TIMESTAMP. Это невозможно, если в коде T-SQL столбец определен как версия строки вместо timestamp.
Есть ли различия между уникальным индексом SQL Server и уникальным ограничением?
Оба могут быть использованы для обеспечения уникальности значений в столбце (столбцах). Создание обоих означает, что SQL Server по умолчанию создает некластеризованный уникальный индекс для этих столбцов. Если в таблице нет кластеризованного индекса, можно создать уникальный индекс, а также уникальное ограничение как кластеризованное. С точки зрения производительности, механизм SQL Server не учитывает, создается ли уникальный индекс как уникальное ограничение или индекс при выборе плана выполнения, и, следовательно, нет разницы в производительности.
Теперь давайте создадим таблицу, а затем уникальный индекс и уникальное ограничение для ее столбцов:
|
CREATE TABLE ##TestTable ( ID INT IDENTITY(1,1), Val1 INT, Val2 INT ) -- Unique index CREATE UNIQUE INDEX UIX_TestTable_Val2 ON ##TestTable(Val1) --Unique constraint ALTER TABLE ##TestTable ADD CONSTRAINT UC_TestTable_Val2 UNIQUE (Val2) SELECT * FROM tempdb.sys.indexes WHERE OBJECT_ID = object_id('tempdb..##TestTable') |
Из последнего запроса мы видим, что независимо от создания уникального ограничения (unique constraint) или уникального индекса (unique index), уникальные некластеризованные индексы были созданы в обоих столбцах. Однако для столбца Val2 ясно показано, что это уникальное ограничение, где is_unique_constraint = 1

Тем не менее, важно упомянуть некоторые технические отличия:
- В отличие от создания уникального индекса, в случае создания уникального ограничения настройка некоторых параметров индекса недоступна как в SSMS, так и в коде T-SQL.
- Невозможно удалить индекс, созданный в результате создания уникального ограничения, с помощью команды DROP INDEX. Вместо этого следует использовать команду DROP CONSTRAINT, которая, в свою очередь, также удаляет связанный индекс.
В целом, для обеспечения уникальности значений в столбце, создания уникальных индексов вместо уникальных ограничений, в некоторых условиях можно рассматривать как более гибкое решение. Это связано с тем, что разработчики имеют больше возможностей при создании индексов с использованием кода T-SQL, а также, в отличие от уникальных ограничений, нет особых предварительных условий для удаления уникальных индексов. Кроме того, нет никаких различий в производительности. Уникальные ограничения могут рассматриваться как способ прояснения значения и цели индекса.
В чем разница между операторами <> и! = (Не равно) SQL Server?
Это одни и те же операторы, и нет различий с точки зрения функциональности или производительности. Оба сравнивают два выражения, и результат будет TRUE, если они не равны. Если они равны, результат будет FALSE. Предполагается, что оба операнда не равны NULL. Вы можете использовать SET ANSI_NULLS, чтобы определить желаемый результат сравнения с NULL.
- Единственное, что стоит упомянуть, это то, что оператор <> является стандартом ISO, а оператор ! = - нет. Во всяком случае, это не имеет никакого значения в их функциональности.
В следующем примере показано простое использование этих операторов:
|
DECLARE @value INT=5 --Using <> IF(@value <> 0) SELECT 20/@value ELSE SELECT 0 --Using != IF(@value != 0) SELECT 20/@value ELSE SELECT 0 |
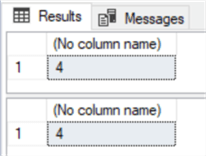
В обоих случаях результат равен «4», потому что @value равен не «0», а «5»:
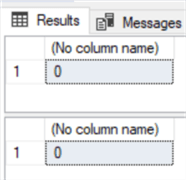
Напротив, в следующем примере мы получим 0 для обоих случаев. Это потому, что 0 = 0 и, следовательно, 0 <> 0 (0! = 0) возвращает FALSE:
|
DECLARE @value INT=0 --Using <> IF(@value <> 0) SELECT 20/@value ELSE SELECT 0 --Using != IF(@value != 0) SELECT 20/@value ELSE SELECT 0 |
Есть ли разница между INNER JOIN и JOIN в SQL Server?
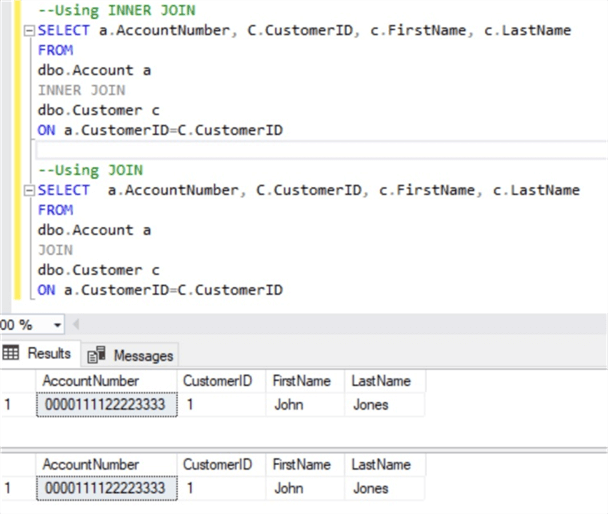
Они абсолютно эквивалентны. JOIN возвращает все строки из двух или более таблиц, где выполняется условие соединения. Он может быть написан со словом INNER и без него и зависит только от предпочтений разработчика:
Аналогично, OUTER может быть пропущен в соединениях LEFT OUTER, RIGHT OUTER и FULL OUTER:
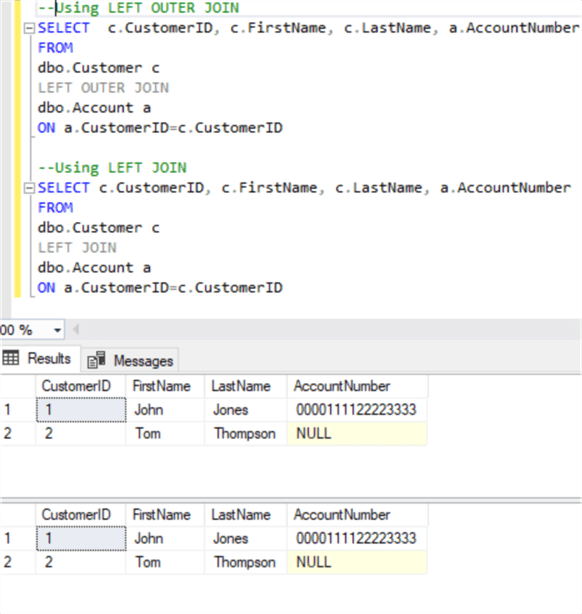
Хотя некоторые разработчики чувствуют себя более комфортно, используя ключевое слово OUTER, утверждая, что это делает код более читабельным, другие, которые не разделяют это представление, всегда пропускают это ключевое слово. В любом случае, ключевое слово OUTER ничего не меняет в результате, поэтому разработчики могут использовать свой предпочтительный стиль.
Заключение
В заключение, это некоторые понятия в SQL Server, которые функционально эквивалентны. Различия между некоторыми из вышеописанных концепций заключаются только в их именах или синтаксисе (таких как десятичные и числовые типы данных, операторы “! =” и “<>”, ключевое слово OUTER в соединениях и т. д.). Существуют и другие концепции, которые функционально эквивалентны, но все же имеют некоторые незначительные различия, связанные с их использованием (например, ограничения UNIQUE INDEX и UNIQUE, а также типы данных timestamp и rowversion).