Выборка данных в службах интеграции SQL Server
Проблема
При разработке пакетов служб SSIS иногда проще работать с образцом набора данных, а не со всем набором данных. В этом совете мы рассмотрим несколько различных способов преобразования данных в SSIS.
Решение
В службах SSIS есть два преобразования, которые помогут нам создать меньшее подмножество данных на основе выборки. Это выборка строк и преобразования в процентах
Использование преобразования выборки SSIS
- Вместо использования полного набора производственных данных можно использовать образец для многократного тестирования пакета для различных условий. Это может быть очень полезно для репликации производственных ошибок на сервере разработки.
- В зависимости от емкости среды (серверы Dev, Test и UAT) размер тестовых данных можно легко настроить.
- Позволяет тестировать модели интеллектуального анализа данных с различными тестовыми данными.
- Позволяет для действий профилирования данных - чтобы понять качество исходных данных.
Преобразование выборки строк SSIS
Преобразование выборки строк SSIS генерирует выборочный набор данных на основе случайного выбора из входного набора данных. Ожидаемое количество записей образцов должно быть введено в преобразование. По умолчанию преобразование генерирует случайное число для выбора входных строк. Поэтому каждый раз, когда вы запускаете преобразование, вы можете получать различный набор записей. Это очень полезно, так как вы можете проверить поток данных для различных наборов репрезентативных данных.
Однако, если вы предпочитаете иметь один и тот же набор данных каждый раз, тогда вы можете определить начальное число. Это можно сделать, включив опцию «Использовать следующее случайное начальное число» («Use the following random seed»)
Это преобразование генерирует два выхода. «Выборка с выбранным выходом» предоставит образец набора данных на основе количества введенных строк, а остальные записи будут доступны через выход «Выборка невыбранных выходных данных».
Свойства семени выборки и значения выборки также можно задать с помощью окна свойств.
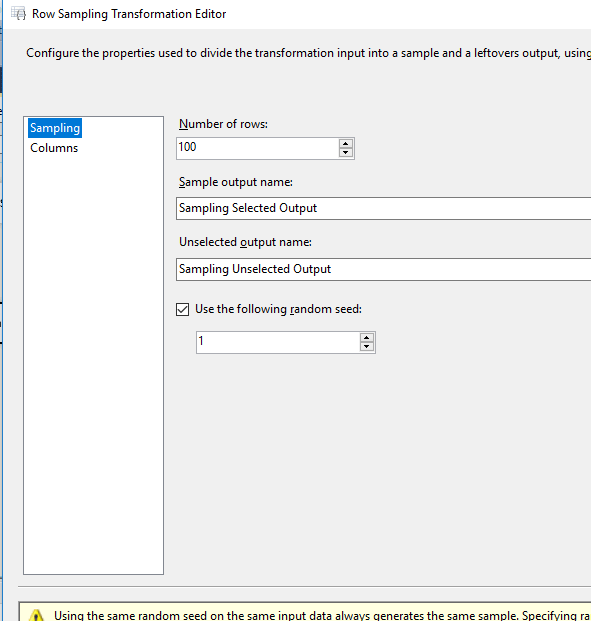
На изображении ниже мы извлекаем данные из Fact InternetSales и хотим собрать 100 записей. Преобразование выборки строки было добавлено, как показано ниже.
![]()
Значение выборки (количество строк) было установлено равным 100. Также начальное значение выборки было установлено равным 1, так что мы получаем одни и те же записи каждый раз, когда мы выполняем это.
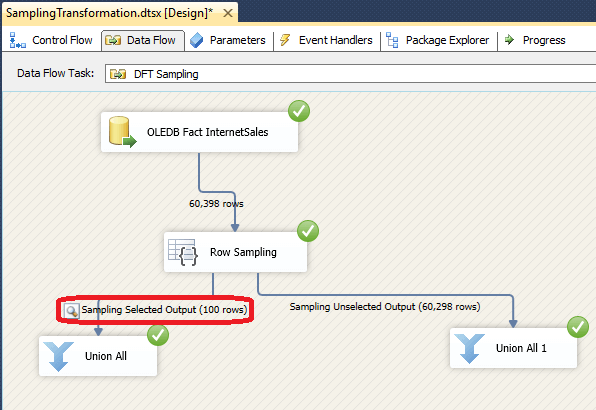
После успешного выполнения мы можем увидеть записи выборки через Sampling Selected Output.
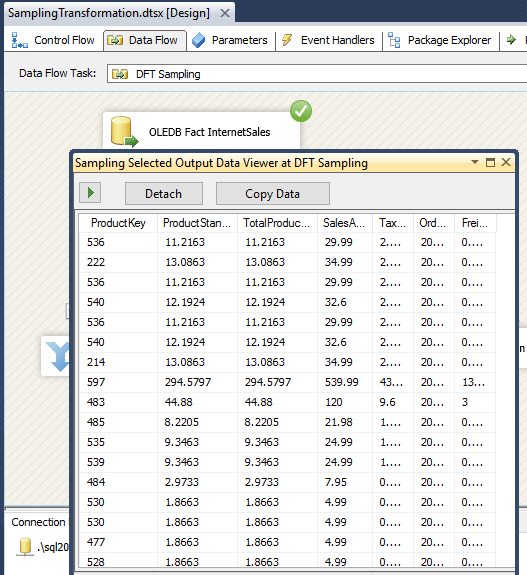
Вьюер данных показывает пример вывода.
Процентная выборка SSIS
Преобразование Percentage Sampling служб SSIS работает так же, как и преобразование «Выборка строк», за исключением того, что мы указываем процент выборочных записей вместо определенного количества записей.
Преобразование «Процентная выборка» использует алгоритм, чтобы определить, должна ли строка быть включена в пример выходных данных. Из-за функциональности алгоритма количество выходных строк не будет точно соответствовать указанному проценту. Предположим, у нас есть исходный набор данных с 10 000 записей, и вы хотите проверить качество данных, выбрав 10% набора данных. В идеале вы ожидаете увидеть 1000 записей, но фактические записи, выбранные службами SSIS, могут быть больше или меньше 1000 записей.
На изображении ниже мы извлекаем данные из Fact InternetSales и хотели бы собрать 10% записей. Процентное преобразование выборки было добавлено, как показано ниже.
![]()
Значение выборки (процентное соотношение строк) было установлено на 1.
![]()
После успешного выполнения мы можем увидеть записи выборки через Sampling Selected Output.
![]()
Резюме
Преобразования выборки имеют широкий спектр применения. В анализе интеллектуального анализа данных как выбранные, так и невыбранные выходные данные могут использоваться для проектирования и тестирования модели. И преобразования выборки строки и процента просты для изучения и настройки.