Необходимость иметь как хранилище данных, так и кубы
Я слышал, что некоторые люди говорят, что если у вас есть хранилище данных, нет необходимости в кубах (когда я говорю «кубы», я имею в виду табличные и многомерные OLAP-модели). И я слышал, как другие говорят, что если у вас есть кубы OLAP, вам не нужно хранилище данных. Я категорически не согласен с обоими этими утверждениями, поскольку почти все клиенты, которые, по моим наблюдениям, строят современное хранилище данных, используют и то, и другое в своих решениях. Вот несколько причин для этого:
Зачем иметь хранилище данных, если можно просто использовать куб?
- Преодоление сложных шагов, чтобы проще построить куб
- Cube - это отделенческое представление (не предполагающий корпоративного решения)
- Легче очистить /объединять/обрабатывать данные в DW
- Обработка куба происходит медленно относительно источников
- Одно место для контроля согласованности данных и имеет одну версию истины
- Использование инструментами, которые нуждаются в реляционном формате
- Cube не имеет всех данных
- Куб может отставать в обновлении данных (обработка потребностей)
- DW - это место для интеграции данных
- Риск получить несколько кубов, которые делают одно и то же
- DW хранит исторические записи
- Из DW легче создавать витрины данных
Причины, чтобы использовать кубы:
- Семантический слой
- Обработка множества одновременных пользователей
- Агрегирование данных для производительности
- Многомерный анализ
- Нет объединений или отношений
- Иерархии, KPI
- Безопасность на уровне строк
- Расширенные расчеты времени
- Медленное изменение размеров (SCD)
- Требуется для некоторых инструментов отчетности.
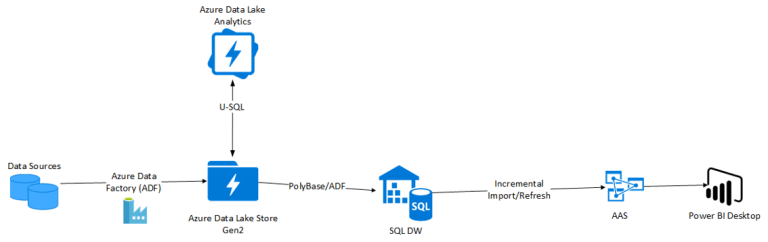
Типичная архитектура должна выглядеть примерно так: