Синхронизируйте локальное хранилище данных с Azure DW с помощью 3 конвейеров ADF
Большинство организаций пытаются перейти в облако для получения сценариев расширенной аналитики, но у них есть одна большая проблема: они вложили десятилетие в локальное хранилище данных, в котором слишком много беспорядочной архитектуры, чтобы его можно было распутать. Мы расскажем о полных параметрах миграции во второй части этого поста, но в этой статье речь пойдет об использовании Azure Data Factory для обеспечения синхронизации на предварительном DW (будь то Teradata, Netezza или даже SQL Server), синхронизированном с Azure SQL DW. на ночной основе. Синхронизация важна, потому что она позволит всем вашим «новым разработкам» происходить в облаке, в то время как на 12-24 месяца вам может понадобиться настоящий проект миграции DW, чтобы перенести устаревшие соединения в новую среду.
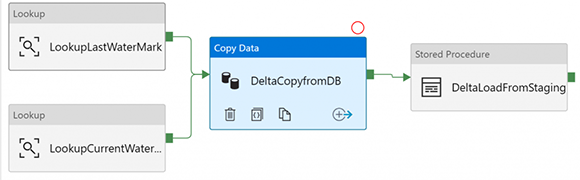
В этой статье предполагается, по крайней мере, некоторое базовое понимание Azure Data Factory V2 (ADF). Рекомендуется также ознакомиться с этой документацией по копированию данных в Azure SQL DW и из него с помощью ADF.
TL;DR
Этот пост посвящен самой сложной части синхронизации данных: работе с обновлениями! Большинство хранилищ данных по-прежнему видят обновленные записи, а шаблоны ADF, предоставленные для «дельта-загрузок», имеют дело только со вставками. На github https://github.com/realAngryAnalytics/adf автор предоставил шаблон ARM для импорта, который включает в себя управляющие таблицы и хранимые процедуры, необходимые для этой работы.
Azure Data Factory V2 и Azure SQL DW Gen 2
Эти продукты настолько выросли за последние пару лет, что многие аналитики взволнованы движением данных и их хранением. С добавлением сопоставления потоков данных ADF теперь имеет реальный механизм преобразования, который визуально эстетичен и прост в использовании. Мы также обнаружили, что при использовании SQL DW Gen 2 время работы Direct Query от таких инструментов, как Power BI, значительно сократилось и начинает делать Direct Query реальной опцией для инструментов BI.
Все, что вам нужно, это 3 конвейера!
Конечно, дьявол всегда в деталях, однако для большинства крупных корпоративных хранилищ данных эти 3 конвейера должны охватывать 98% ваших сценариев. Вам может понадобиться пользовательский конвейер здесь или там, но идея состоит в том, чтобы написать 3 общих конвейера и использовать управляющие таблицы и параметры для обработки сотен или тысяч таблиц.
- Начальная загрузка данных (будет обсуждаться в части 2, но шаблон можно найти здесь.
- Усечение и перезагрузка небольших таблиц (мы обсудим в части 2, но, безусловно, самый простой из трех)
- Дельта загружает, включая обновления (в центре внимания этого поста)
Delta Loads и работа с обновлениями
В этом посте мы рассмотрим самую сложную часть синхронизации данных, которая заключается в обновлении записей при дельта-загрузке. Azure Data Factory предоставляет шаблон для дельта-загрузок, но, к сожалению, он не работает с обновленными записями.
Пример набора данных
В этом примере используется база данных SQL Azure с установленной программой Adventure Works DW 2016. Можно загрузить ее здесь.
Мы используем таблицу FactResellerSales и сделаем начальную синхронизацию с SQL DW Azure, а затем выполним вставки и обновления в исходном наборе данных и проследим, чтобы они правильно отображались.
Подготовка исходной базы данных
Запустите сценарий подготовки данных:
https://github.com/realAngryAnalytics/adf/blob/master/sqlscripts/delta_load_w_updates/sourcedatabaseprep.sql
Здесь нужно сделать две основные вещи:
- Создайте новую схему с именем [ANGRY] в исходной базе данных, создайте таблицу FactResellerSales и скопируйте сюда исходные данные, чтобы мы не мешали исходным образцам таблиц, которые вы, возможно, захотите использовать для чего-то другого позже.
- Измените таблицу, чтобы добавить «ModifiedDate» и первоначально заполните исходной OrderDate.
Необходимо иметь измененные даты в таблицах Delta Load
Это единственное условие, которое вы будете иметь в своем хранилище данных. Таблицы, которые вы не можете украчивать и перезагружать, будут представлять собой таблицы фактов/транзакций, и обычно должна существовать концепция измененной даты. Но иногда этого не происходит, и это усилие необходимо будет предпринять, чтобы сделать эту работу.
Подготовка назначенной базы данных
Синтаксис в приведенном ниже сценарии подготовки данных предназначен для Azure SQL DW. Есть некоторые отличия SQL от стандартного SQL Server. Помните об этом
Запустите сценарий подготовки данных:
https://github.com/realAngryAnalytics/adf/blob/master/sqlscripts/delta_load_w_updates/destdatabaseprep.sql
В этом сценарии многое происходит и стоит его рассмотреть. Основные моменты заключаются в следующем:
- Создание новой схемы [ANGRY] (как в исходном коде)
- Создание таблицы водяных знаков и хранимой процедуры update_watermark (подробно описано в базовом шаблоне дельта-загрузки: https://docs.microsoft.com/en-us/azure/data-factory/solution-template-delta-copy-with-control-table)
- Заполните таблицу водяных знаков начальной датой использования (01.01.1900 будет означать, что наш первый запуск конвейера будет реплицировать все данные из источника FactResellerSales в целевой SQL DW).
- Создайте таблицу FactResellerSales (измените с помощью ModifiedDate)
Как обрабатывать обновления
Для наиболее эффективного выполнения обновлений у вас должна быть промежуточная таблица для каждой таблицы, которая будет выполнять дельта-загрузки. Он будет иметь идентичный DDL для фактической таблицы (FactResellerSales), за исключением того, что это будет таблица HEAP
Также будет таблица дельта-контроля, которая будет содержать столбцы первичного ключа, которые будут определять уникальность записи для каждой таблицы. Наша реализация обрабатывает до 6 ключевых столбцов. Если у вас больше, вам придется изменить таблицу и хранимую процедуру.
Примечание. Возможность обработки уникального ограничения из нескольких столбцов очень важна для обработки исходных DW, таких как Teradata.
|
/* This is specific to the concept of being able to handle delta loads that may contain updates to previously loaded data */ CREATE TABLE [ANGRY].[deltacontroltable]( [TableName] [varchar](255) NULL, [WatermarkColumn] [varchar](255) NULL, [KeyColumn1] [varchar](255) NULL, [KeyColumn2] [varchar](255) NULL, [KeyColumn3] [varchar](255) NULL, [KeyColumn4] [varchar](255) NULL, [KeyColumn5] [varchar](255) NULL, [KeyColumn6] [varchar](255) NULL ) WITH ( CLUSTERED INDEX (TableName) ); GO
/* Insert into deltacontroltable the metadata about the destination table and the key fields that are needed to get a unique record. For FactResellerSales this is SalesOrderNumber and SalesOrderLineNumber */ INSERT INTO ANGRY.deltacontroltable values ('ANGRY.FactResellerSales','ModifiedDate','SalesOrderNumber','SalesOrderLineNumber',null,null,null,null); |
Наша таблица FactResellerSales требует двух ключей для определения уникальности: «SalesOrderNumber» и «SalesOrderLineNumber». Оператор insert включен в код выше.
Неиспользуемые ключевые столбцы остаются пустыми. У нас также есть WatermarkColumn в реализации, однако его необходимость не была определена, так что можно его опустить.
Волшебная хранимая процедура
Хранимая процедура delta_load_w_updates (в сценарии destdatabaseprep.sql, связанном выше) использует управляющую таблицу, таблицу приемников и промежуточную таблицу для создания динамического sql, который удалит записи из источника данных приемника, если они существуют, а затем вставит все записи из промежуточной обработки стол навалом. Обратите внимание, что пример сгенерированного SQL ниже не использует INNER JOIN непосредственно в DELETE, так как SQL DW не будет его поддерживать.
|
/* Example output of the stored procedure */ DELETE ANGRY.FactResellerSales WHERE CAST(SalesOrderNumber as varchar(255)) + '|' + CAST(SalesOrderLineNumber as varchar(255)) IN (SELECT CAST(t2.SalesOrderNumber as varchar(255)) + '|' + CAST(t2.SalesOrderLineNumber as varchar(255)) FROM ANGRY.FactResellerSales_Staging t2 INNER JOIN ANGRY.FactResellerSales t1 ON t2.SalesOrderNumber = t1.SalesOrderNumber AND t2.SalesOrderLineNumber = t1.SalesOrderLineNumber) |
С помощью хранимой процедуры, которая выполняет описанные выше действия DELETE и INSERT на основе уже существующих записей и INSERT всех данных, дата модификации которых больше, чем последний водяной знак, мы можем теперь перейти к нюансам конвейера ADF, чтобы учесть разницу между базовой дельта-загрузкой шаблон и эта новая версия, которая будет обрабатывать обновления.
Развертывание Data Factory
Сначала мы развернем фабрику данных, а затем рассмотрим ее.
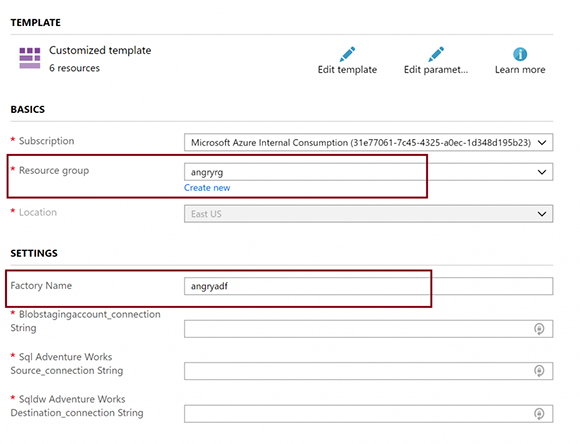
На портале Azure (https://portal.azure.com) создайте новый ресурс Azure Data Factory V2. Наш назван «angryadf». Запомните имя, которое вы дадите, так как приведенное ниже развертывание создаст ресурсы (соединения, наборы данных и конвейер) в этом ADF.
Эта ссылка развернет активы фабрики данных, включая конвейер delta_load_w_updates. Примечание: произойдет сбой, если вы еще не создали фабрику данных.
Это шаблон, который требует три строки подключения:
- Строка соединения с учетной записью хранилища BLOB-объектов - будет использоваться для постановки загрузки в SQL DW. Это можно найти в диалоговом окне «Keys» вашей учетной записи хранения BLOB-объектов.
- Исходная строка подключения базы данных Azure SQL - будет источником. Находится в диалоге «settings -> Connection Strings». Использование SQL-аутентификации, вероятно, проще всего. Замените записи «User ID» и «Password» реальными значениями, иначе развертывание не удастся. Даже если вы решите использовать Teradata, Netezza или SQL локально для источника, продолжайте и используйте базу данных SQL Azure для развертывания шаблона, тогда вы можете изменить источник. (это будет стоить вам 5 долларов в месяц)
- Место назначения Строка подключения хранилища данных Azure SQL - будет местом назначения. Как и Azure SQL DB, она находится в диалоговом окне «settings -> Connection Strings». Не забудьте изменить свой идентификатор пользователя и пароль.
Или вы можете импортировать файл azuredeploy.json (шаблон ARM) с https://adf.azure.com из корня github https://github.com/realAngryAnalytics/adf/blob/master/azuredeploy.json
Проверьте конвейер
Этот конвейер основан на исходном шаблоне дельта-загрузки, поэтому мы рассмотрим только основные различия, которые были реализованы.
Примечание. На приведенных ниже снимках экрана широко используются параметры, и если вы не знакомы с функцией «Add Dynamic Content», это может показаться более сложным, чем на самом деле. Использование «Add Dynamic Content» позволяет создавать выражения визуально.
Использование параметров для передачи в конвейер - это то, как вы можете сделать его универсальным для работы с любой дельта-нагрузкой. Мы добавили значения по умолчанию для всех из них, чтобы работать с этим примером, и один дополнительный параметр был добавлен для промежуточной таблицы назначения:
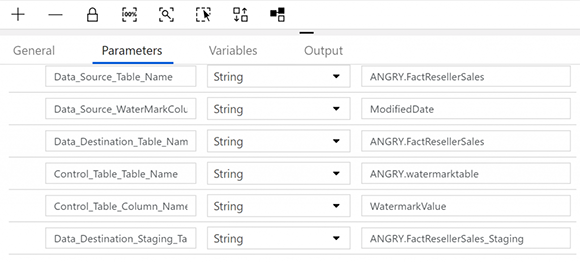
В операции копирования вместо вставки непосредственно в ту же таблицу в приемнике она вставляется в промежуточную таблицу.
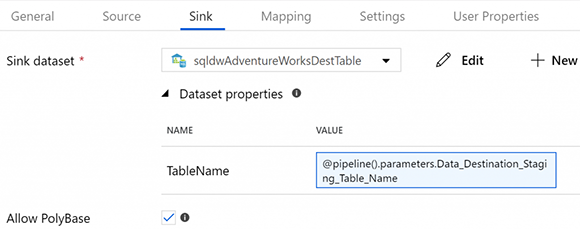
Примечание. Как видно из приведенного выше снимка экрана, мы также предпочитаем параметризовать имя таблицы для объектов набора данных источника и приемника. У ADF плохая привычка создавать отдельные наборы данных для каждой таблицы, которая выходит из-под контроля. Использование параметра TableName позволяет вам создать один исходный набор данных и один приемный набор данных.
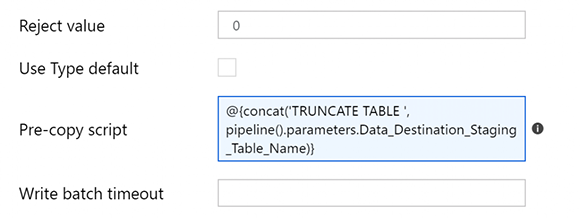
Также в операции копирования есть действие сценария предварительной копии, которое собирается укоротить промежуточную таблицу перед каждым запуском. Это означает, что после каждого запуска записи оставляются в промежуточной таблице (предположительно на один день) для выявления любых ошибок до следующего запуска конвейера и усечения строк перед вставкой записей следующего дня.
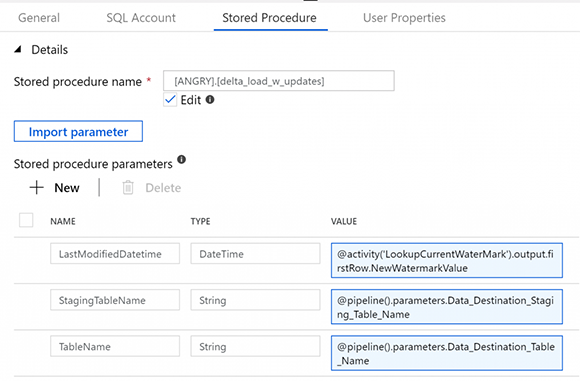
И наконец, действие хранимой процедуры, которое мы изменили с оригинала, который только что обновил таблицу водяных знаков, на процедуру delta_load_w_updates, которую мы создали выше. Эта процедура позволяет перейти от промежуточной к основной таблице, а затем обновляет встроенную таблицу водяных знаков.
Начальный запуск (начальная загрузка всех данных в SQL DW)
В конвейере убедитесь, что он действителен, установив флажок «Validate», а после исправления любых ошибок нажмите «Debug».
Примечание: вводятся значения по умолчанию для всех параметров конвейера. Если вы изменили имя схемы или использовали другую таблицу, их придется изменить.

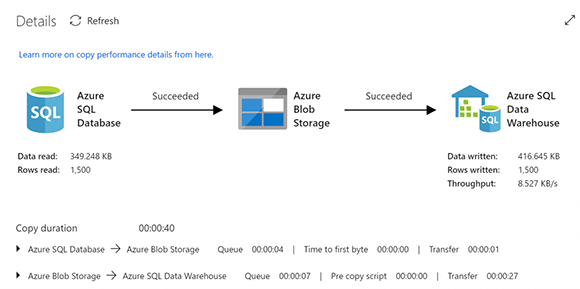
Во время отладки вы получите вывод для каждого действия. В столбце «Actions» вы можете получить входные и выходные данные, а также просмотреть подробную информацию об операции копирования, щелкнув значок очков.
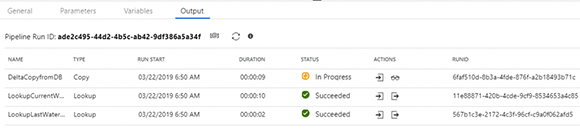
Подробности копирования деятельности:
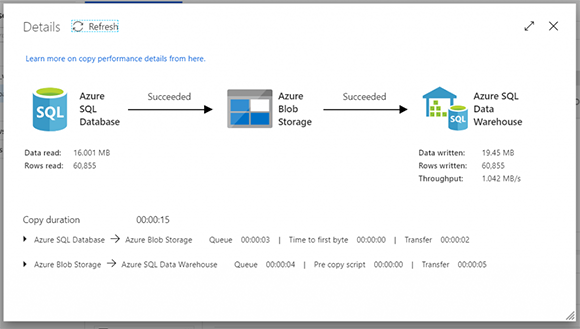
Вы можете запустить приведенные ниже операторы SQL, чтобы увидеть, что все строки были скопированы в промежуточную таблицу, а затем в основную таблицу, и что таблица водяных знаков была обновлена с помощью MAX ModifiedDate в источнике (который случается 29.11.2013). для нашего старого набора данных AdventureWorks)
|
select count(*) from [Angry].[FactResellerSales] select count(*) from [Angry].[FactResellerSales_Staging] select * from [Angry].[watermarktable] |
Вставьте и измените записи в источнике
Запустите приведенный ниже скрипт, чтобы создать очень простой генератор данных FactResellerSales, который принимает первый ввод как количество вставленных записей, а второй - как количество обновленных записей, которые вы хотите использовать.
https://github.com/realAngryAnalytics/adf/blob/master/sqlscripts/delta_load_w_updates/advworks_datagenerator.sql
Итак, давайте синтетически создадим 1000 новых записей и 500 измененных записей на основе исходного набора данных.
|
exec ANGRY.sp_generate_advworks_data 1000, 500 |
Проверьте создание новых и измененных записей в исходном наборе данных.
|
/* First query retrieves the inserts, second query retrieves the updates, third query should be total */ select count(*) from ANGRY.FactResellerSales where OrderDateKey = 0; select count(*) from ANGRY.FactResellerSales where OrderQuantity = 42; select count(*) from Angry.FactResellerSales where ModifiedDate = (select MAX(ModifiedDate) from ANGRY.FactResellerSales); |
Примечание. Цель этого примера - продемонстрировать возможность, а не иметь реалистичные данные, поэтому все вставленные записи имеют нули почти для всех целочисленных значений, а обновления просто обновили OrderQuantity до 42.
Запустите конвейер снова. Обратите внимание, что вы можете просмотреть результаты первых двух действий поиска, нажав на значок действий ниже.
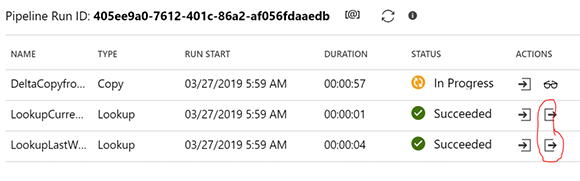
Ниже, первое значение является последним водяным знаком (полученным из таблицы водяных знаков), а второе значение является текущим водяным знаком (полученным из максимального значения в исходной таблице).
|
{ "firstRow": { "TableName": "ANGRY.FactResellerSales", "WatermarkValue": "2013-11-29T00:00:00Z" }, "effectiveIntegrationRuntime": "DefaultIntegrationRuntime (East US 2)" } { "firstRow": { "NewWatermarkValue": "2019-03-26T19:56:59.29Z" }, "effectiveIntegrationRuntime": "DefaultIntegrationRuntime (East US)" } |
Операция копирования будет извлекать все из исходной таблицы между этими двумя датами на основе исходного SQL, который создается в поле «Query».
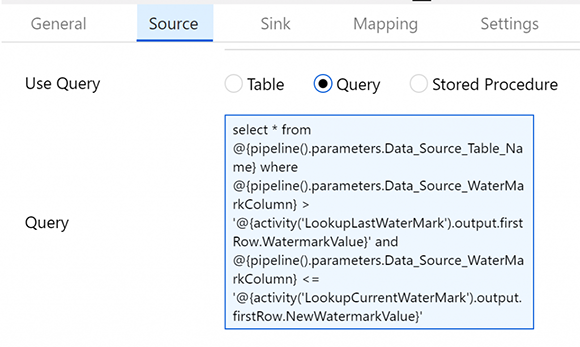
Просматривая подробную информацию об операции копирования, вы должны увидеть 1500 записей.
Запустите те же запросы, которые вы выполняли для исходной таблицы сейчас, к промежуточной таблице, чтобы увидеть вставленные и измененные записи.
К сожалению, нет хорошего представления о том, что произошло в активности хранимых процедур. Все, что мы можем видеть, это вводы и выводы, как показано ниже:
|
{ "storedProcedureName": "[ANGRY].[delta_load_w_updates]", "storedProcedureParameters": { "LastModifiedDatetime": { "value": "2019-03-26T19:56:59.29Z", "type": "DateTime" }, "StagingTableName": { "value": "ANGRY.FactResellerSales_Staging", "type": "String" }, "TableName": { "value": "ANGRY.FactResellerSales", "type": "String" } } } { "effectiveIntegrationRuntime": "DefaultIntegrationRuntime (East US 2)", "executionDuration": 4239 } |
Чтобы реализовать это в работе, вы, вероятно, захотите укрепить хранимую процедуру, добавив транзакцию / откат и некоторые результаты проверки.
Тем не менее, вы должны увидеть в таблице назначения (выполнив те же запросы, что и выше), что вы успешно вставили 1000 записей и обновили 500 существующих записей.
Поздравляем, теперь у вас есть код SQL и конвейер ADF, который выполняет сложнейшую часть синхронизации хранилища данных с облаком, которое занимается обновлениями.
Как это меняется, если источником является Teradata или Netezza?
В этом примере использовался источник SQL, однако с Teradata или Netezza не должно быть особых изменений. Дважды проверьте синтаксис запроса для вашего источника, но оба действия «LookupCurrentWatermark», а также действие «DeltaCopyFromDB» должны быть стандартным T-SQL, но, тем не менее, стоит проверить, есть ли у вас ошибки.
Однако нужно удостовериться в том, что в действии «DeltaCopyFromDB» на вкладке приемника «Use Type default» НЕ проверяется.
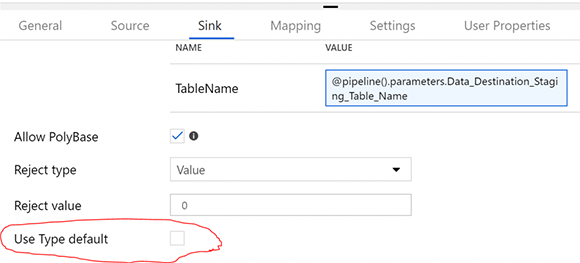
В SQL Server это, кажется, не имеет значения, но при копировании нулевых значений для числовых полей из Teradata это приведет к ошибке polybase с ошибкой «empty string cannot be converted to a decimal».
Расширение до 100 таблиц
Таким образом, мы сделали это только для одной таблицы, но с этим конвейером и двумя другими можно справиться с целым хранилищем данных. Если вы знакомы с ADF (которым вы должны быть, если вы пережили всю эту статью), то вы знаете, что можете создавать триггеры с разными входными параметрами для обработки разных таблиц. Для каждой новой таблицы, которую вы хотите выполнить дельта-загрузками, потребуется запись в deltacontroltable, а также новая промежуточная таблица. Это просто стоимость ведения бизнеса для достижения успеха в облаке. Это довольно простая работа по вводу данных, через пару дней написания сценариев вы можете автоматизировать ее.
Еще одна вещь, на которую следует обратить внимание: если вы потопите хранилище данных, помните, что исходное DW находится ниже по потоку от существующих процессов ETL. Теперь мы добавляем дополнительную обработку, которая должна быть завершена в конце ваших существующих ночных нагрузок. Таким образом, даже несмотря на то, что вы могли бы создать сотни запланированных триггеров в ADF с различными параметрами, необходимыми для каждой дельта-загрузки, более реалистично, что вы захотите запустить конвейер дельта-загрузки как событие, как только эта таблица будет загружена в исходное DW. Это может быть достигнуто с помощью ADF API.